Introduction
- Why data analytics matters
- How decisions use information
- What counts as data?
- Time dimensions in data
- The data analyst role and ecosystem
- Large language models (LLMs) in the workflow
Why data analytics matters
Almost everything online leaves a trace: messages, clicks, streams, purchases. Learning to work with that information helps make clearer decisions at home and at work.
The U.S. Bureau of Labor Statistics expects strong growth in data-related jobs—on the order of by 2033 compared with many other fields—so demand for people who can read data is unlikely to fade soon.
How decisions use information
Not every choice needs a spreadsheet. Roughly three styles show up in practice:
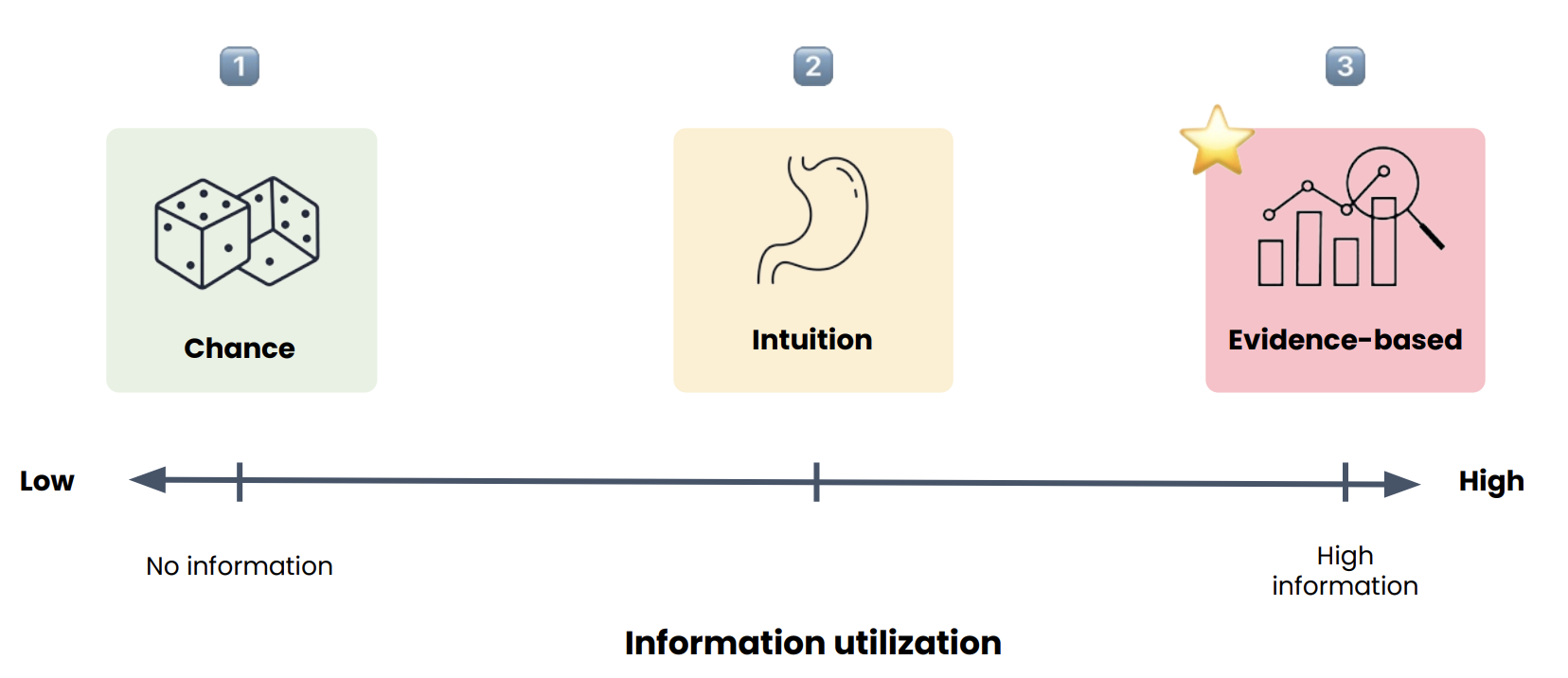
- Chance: Flip a coin; no real use of data.
- Intuition: Decide quickly from experience or gut feel—little formal evidence.
- Evidence-based: Use data, charts, experiments, or models so the reasoning can be checked.
Example (low stakes): A shop owner extends opening hours by one hour on Saturdays. If the downside is small, intuition may be enough.
Example (high stakes): A hospital plans bed capacity or a fund allocates millions. The cost of being wrong is large, so the effort put into gathering and checking data should grow with the impact of the decision.
What counts as data?
Data is information that could change a decision if understood properly.
Unstructured vs structured
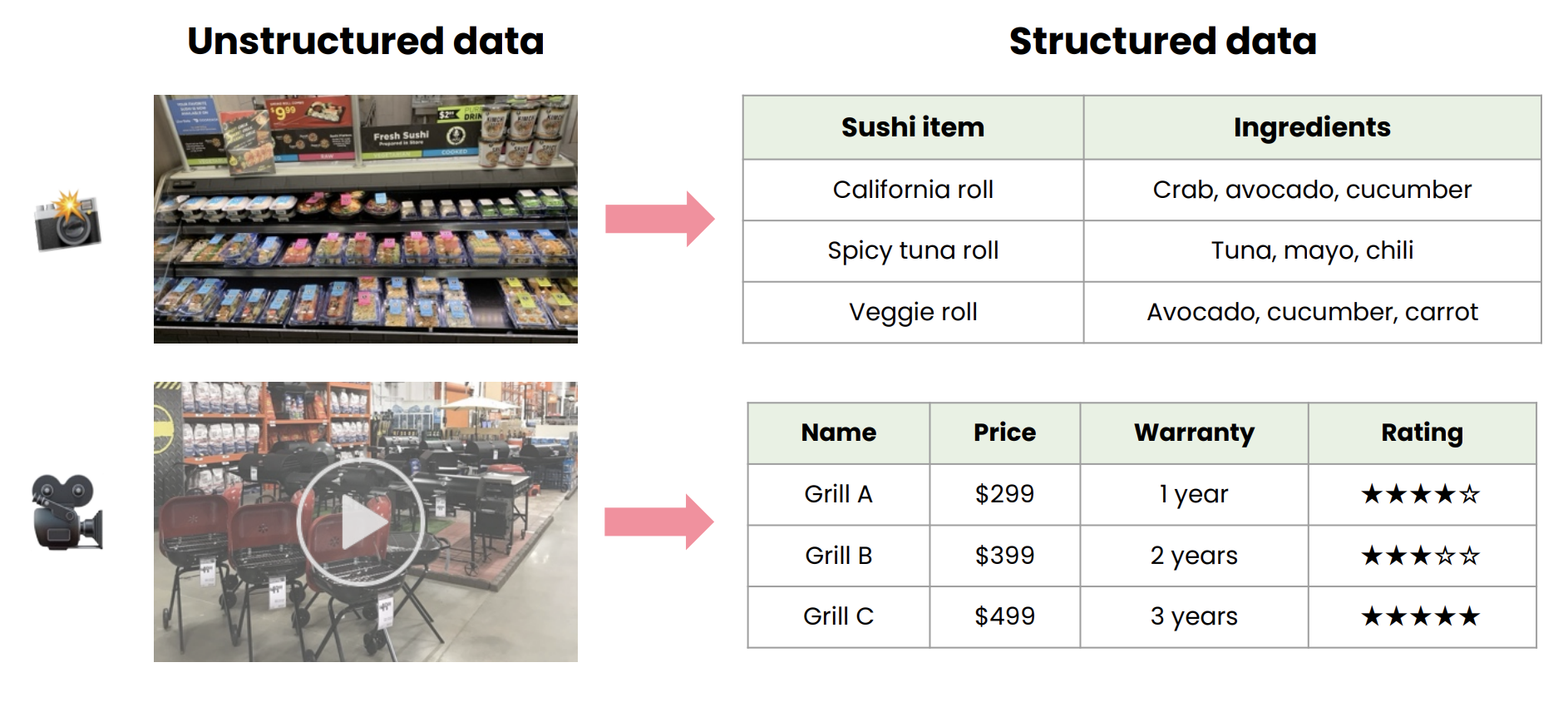
- Unstructured: Natural for humans, awkward for tables—photos, voice notes, long reviews, video. You usually clean or label it (translation, sentiment, tags) before serious analysis.
- Structured: Rows and columns—spreadsheets, order tables, sensor readings logged every minute. This is where classic reporting and many models start.
Simple variable types (structured data)
- Numbers: Counts (e.g., “4 people”) vs measurements (e.g., “3.2 miles”).
- Categories: Labels that group rows—workout type “Legs / Core / Back,” product tier “Basic / Pro,” and so on.
Time dimensions in data
Time is not just an extra column; it changes what question you are asking.
Time series data
Time series data follows the same thing across many points in time. You care about change, trends, or seasonality.
Example: Log daily running mileage every day for a month. Each row might be “date + miles that day.” The story is how effort drifts over time, not a single snapshot.
Cross-sectional data
Cross-sectional data is a snapshot at one moment: many units (or one unit’s profile) observed once.
Example: Open an Instagram profile today and record follower count and bio text once. You are not tracking how followers moved over weeks; you captured one slice in time. A survey of 500 customers on a single day is cross-sectional for the same reason.
Contrast: Same 500 customers surveyed every month becomes a panel (mix of cross-section + time series). For foundations, remembering series vs snapshot is enough.
The data analyst role and ecosystem
Analytics is rarely solo work. Collaboration is normal: syncs with product, marketing, operations, or a central data team.
Analyst as the link in the chain
The analyst sits between people who generate data, people who move and store it, and people who consume it:
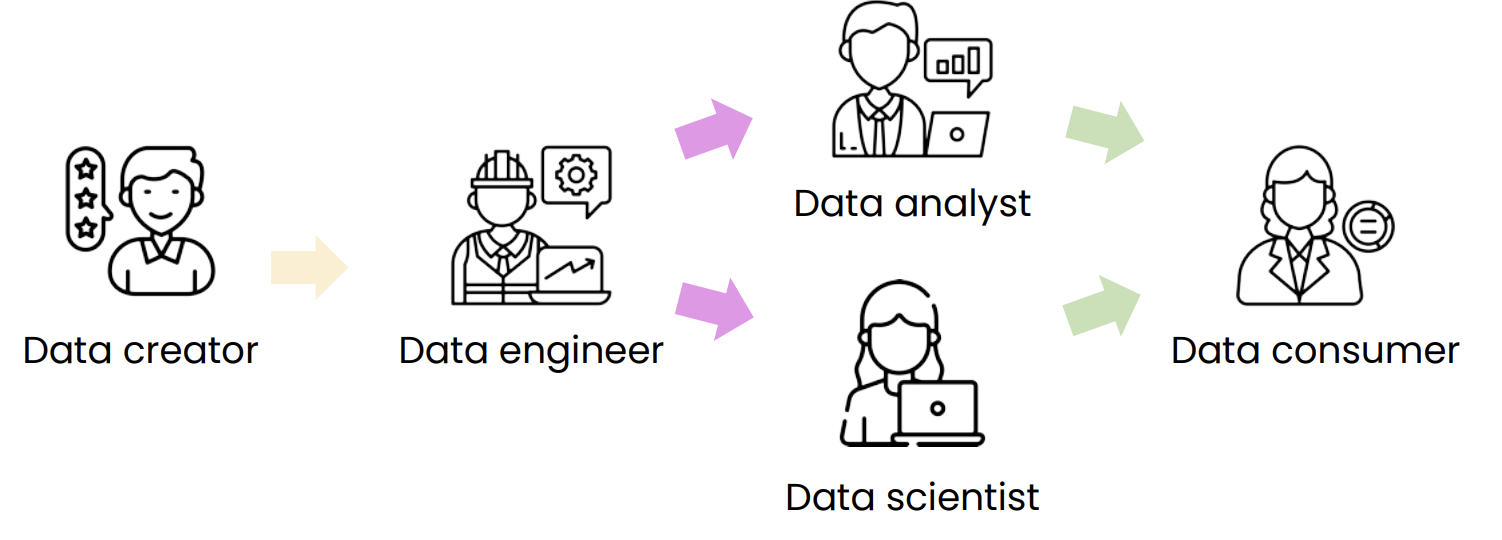
- Data creators produce events and records (apps, sales systems, clinicians entering forms).
- Data engineers build pipelines, warehouses, and reliable tables so analysts are not scraping raw logs by hand every week.
- Data analysts turn questions into queries, charts, and recommendations—and explain limits (“this is correlation, we have not run an experiment”).
- Data consumers (managers, PMs, clinicians, investors) use the output to decide what to ship, fund, or change.
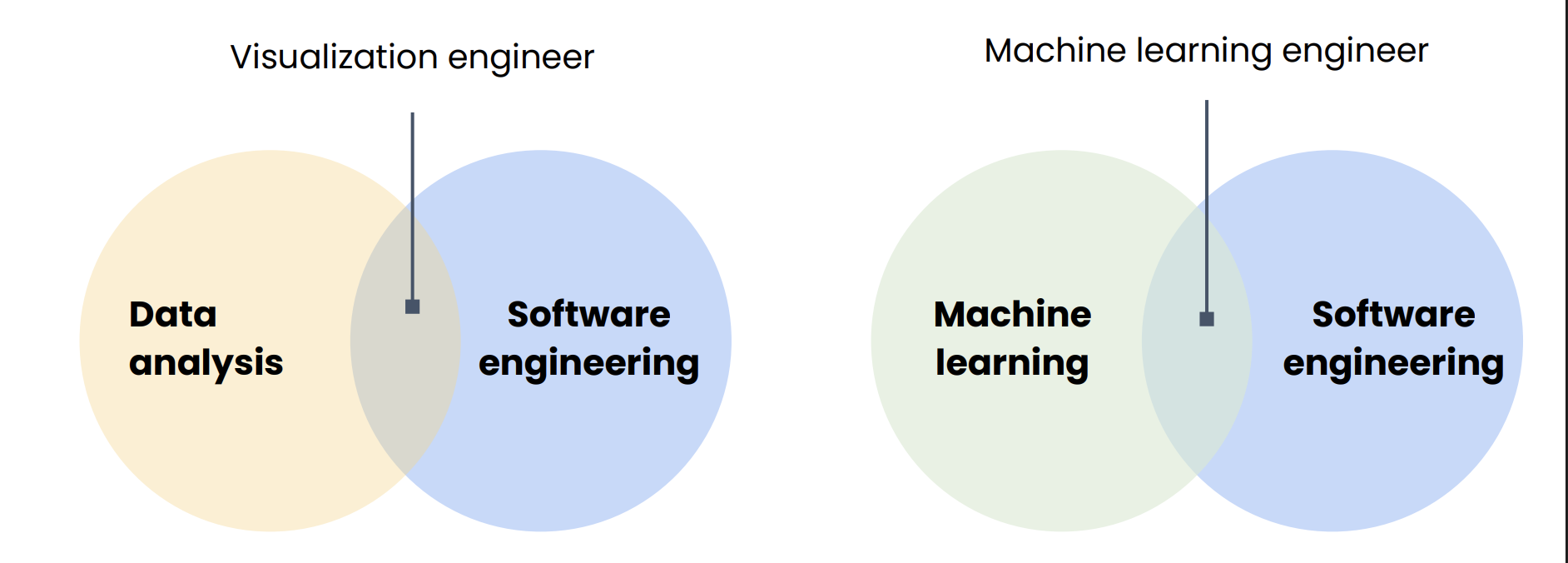
In practice the arrows are messier (analysts talk to creators; engineers join scoping meetings), but this picture captures the handoff of responsibility: from raw activity → dependable data → insight → decision.
Large language models (LLMs) in the workflow
Generative AI tools based on LLMs can draft text, suggest spreadsheet formulas, or summarize long documents. They are helpers, not sources of truth.
Under the hood, an LLM is trained to predict the next word (token) from context, then adjusted so it follows instructions in chat. That is why it can sound authoritative even when it is wrong.