Region Proposals and Semantic Segmentation: U-Net
- Region Proposals
- Semantic Segmentation
- Transpose Convolutions (Deconvolution)
- U-Net Architecture Intuition
- U-Net Architecture (Full Design)
- Summary
Region Proposals
Why Region Proposals?
Traditional object detectors like sliding windows are computationally expensive due to scanning every possible region in the image. Region Proposal methods address this by generating a small number of candidate regions likely to contain objects.
Selective Search

- Group similar pixels into superpixels
- Merge regions based on similarity
- Outputs ~2000 proposals per image
R-CNN Pipeline
- Use Selective Search to propose regions.
- Warp each region to a fixed size (e.g., 224x224).
- Pass through a ConvNet to extract features.
- Use SVMs for classification and regressors for bounding boxes.
Limitation: Very slow due to independent ConvNet run on each region.
Semantic Segmentation
What is Semantic Segmentation?
Semantic segmentation is the task of classifying each pixel of an image into a class label.
- Image Classification: What is in the image?
- Object Detection: Where is the object?
- Semantic Segmentation: Which pixel belongs to which class?
Applications
- Medical imaging (e.g., tumor segmentation)
- Autonomous driving (lane and pedestrian detection)
- Satellite image analysis
- Industrial defect detection
Transpose Convolutions (Deconvolution)
Motivation
In segmentation tasks, we need to upsample feature maps back to the original image size. Transpose convolutions (a.k.a. deconvolutions) help with this.
How It Works
A transpose convolution is the reverse of a normal convolution:
- While convolution reduces spatial size (downsampling),
- Transpose convolution increases it (upsampling).
Mathematical Operation
Suppose an input size of and a kernel size of with stride .
-
Convolution output size:
-
Transpose convolution (reverses the above):
Alternatives
- Nearest-neighbor or bilinear upsampling + 1x1 conv (cheaper, less expressive)
- Learned transpose convolutions (richer)
U-Net Architecture Intuition
Key Idea
U-Net is a fully convolutional network that consists of:
- A contracting path to capture context (downsampling)
- An expanding path to enable precise localization (upsampling)
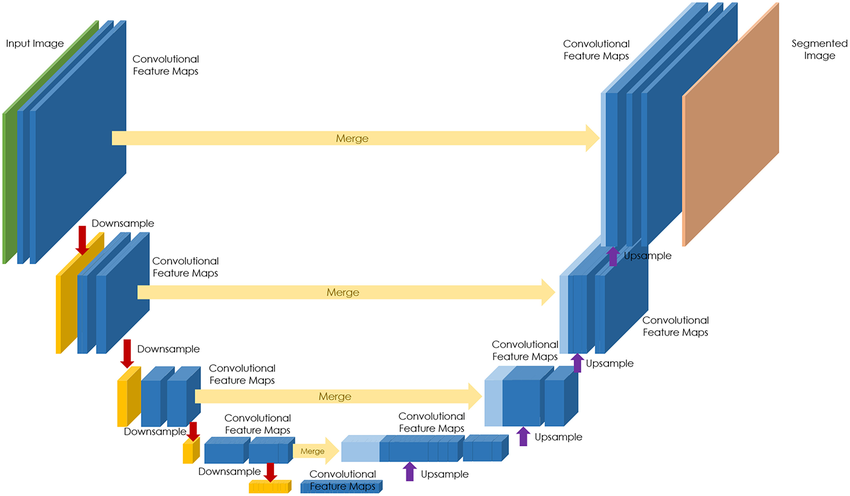
U-Net was originally designed for biomedical image segmentation but is now used in many fields.
Contracting Path (Encoder)
- Similar to standard CNN (e.g., VGG)
- Repeated 2x:
- Conv (ReLU) → Conv (ReLU) → MaxPooling
Expanding Path (Decoder)
- Transpose convolution for upsampling
- Skip connections concatenate features from encoder
Why Skip Connections?
Skip connections pass high-resolution features from encoder to decoder, enabling:
- Better boundary localization
- Preservation of fine details
U-Net Architecture (Full Design)
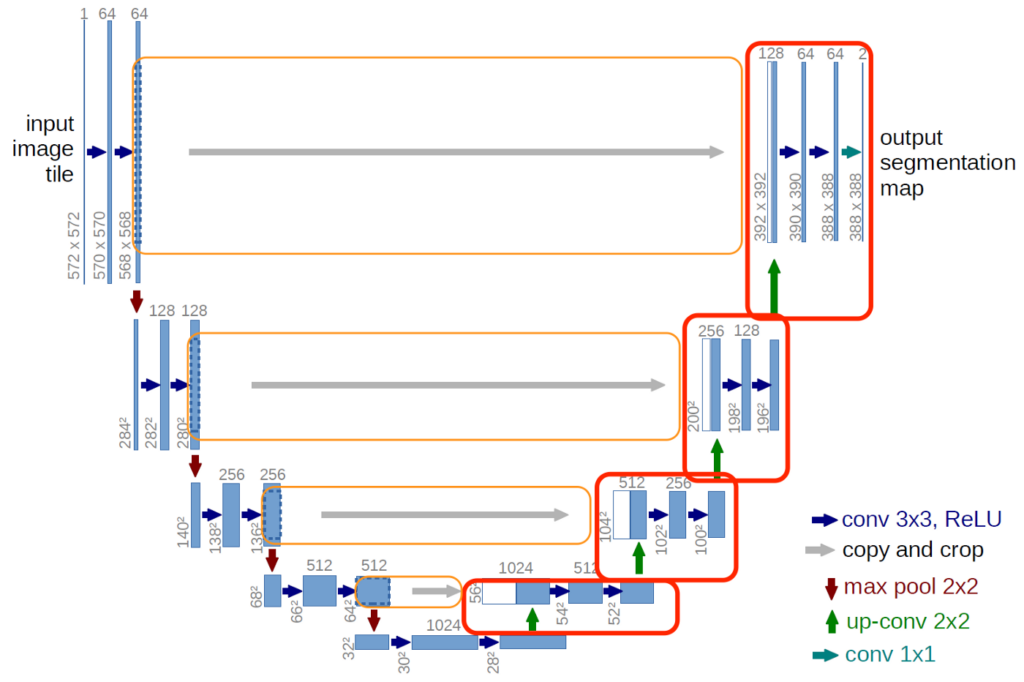
Structure Overview
- Input size:
- Each layer: two convolutions + ReLU
- Downsampling: max-pooling
- Upsampling: transpose convolutions
- Final output: convolution to map to classes (per pixel)
Example Architecture
Input → Conv → Conv → Pool
↓ ↑
Conv → Conv → Pool
↓ ↑
Conv → Conv → Pool
↓ ↑
Bottleneck ← Skip Connections
↓ ↑
Upconv → Concat → Conv → Conv
↓
Output (Segmentation Map)
Loss Function
Typical loss: Pixel-wise cross-entropy loss.
Where:
- : height and width of the image
- : number of classes
- : ground truth indicator (1 if pixel belongs to class )
- : predicted probability for class at pixel
Performance Metrics
- Pixel Accuracy: overall correct classification
- IoU per class: same as object detection, applied per-pixel
- Dice Coefficient: common in medical segmentation
Summary
- Region proposals are key to efficient object detection pipelines like R-CNN.
- Semantic segmentation classifies each pixel and requires upsampling layers.
- Transpose convolutions allow learned upsampling.
- U-Net combines low-level and high-level features through skip connections and is state-of-the-art for many segmentation tasks.