Natural Language Processing and Word Embeddings
- Word Representation
- Using Word Embeddings
- Properties of Word Embeddings
- Embedding Matrix
- Learning Word Embeddings
- Word2Vec
- Negative Sampling
- GloVe Word Vectors
- Sentiment Classification
- Debiasing Word Embeddings
Word Representation
In Natural Language Processing (NLP), word representation refers to how words are converted into a numerical form that a machine learning model can understand. Traditional approaches used one-hot encoding, where each word is represented by a binary vector of the vocabulary size. However, one-hot vectors suffer from high dimensionality and no semantic information.
Example:
This image shown one-hot embedding example.
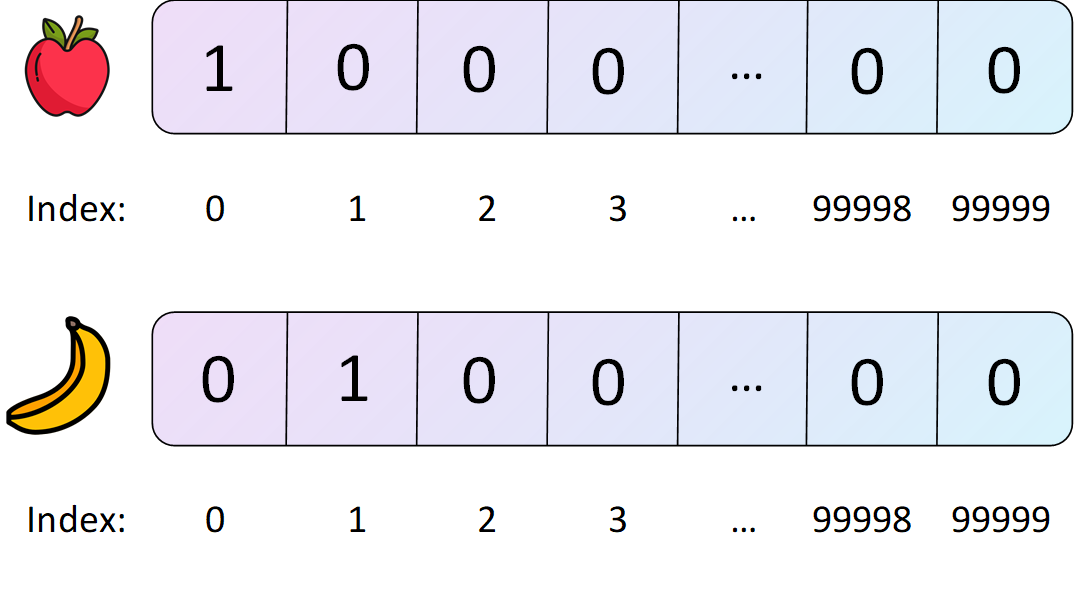
Vocabulary: ["king", "banana", "apple"]
One-hot representation of "king": [1, 0, 0]
One-hot representation of "banana": [0, 1, 0]
One-hot representation of "apple": [0, 0, 1]
This representation doesn’t capture the relationship between “banana” and “apple” or that both are fruit. Hence, we need better methods like word embeddings.
Using Word Embeddings
Word embeddings are dense vector representations of words in a continuous vector space, where semantically similar words are mapped closer together.

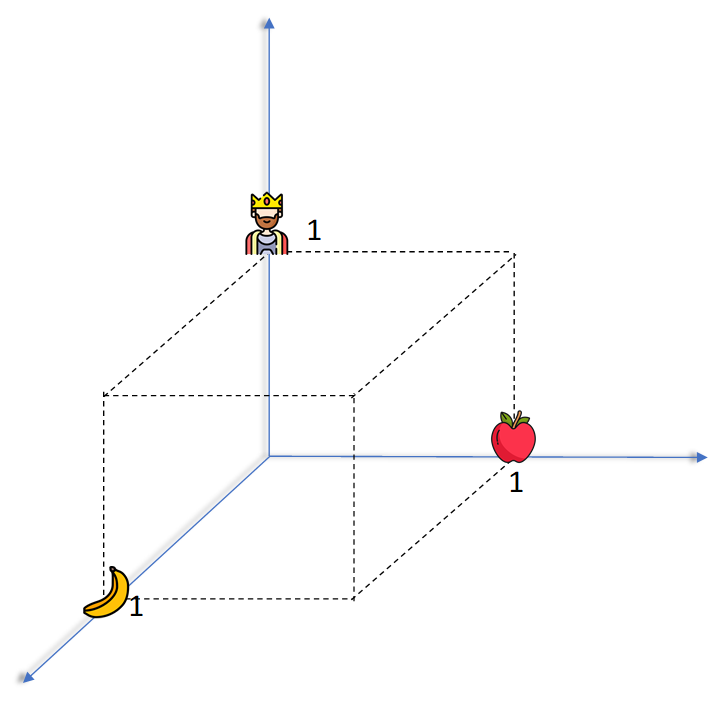
Example: A 3D visualization might show vectors such that:
- vector(“king”) - vector(“man”) + vector(“woman”) ≈ vector(“queen”)
This arithmetic reflects the semantic relationship between the words, allowing machines to understand analogies.
Properties of Word Embeddings
Word embeddings exhibit fascinating properties:
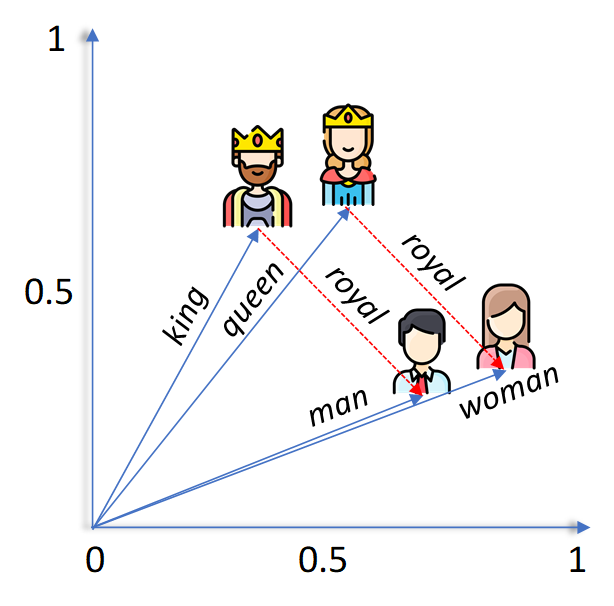
- Semantic similarity: Similar words have vectors close to each other (e.g., “good” and “great”).
- Linear substructures: Relationships can be captured with simple vector arithmetic (e.g., “Paris” - “France” + “Italy” ≈ “Rome”).
- Dimensionality reduction: Embeddings reduce high-dimensional one-hot vectors to lower-dimensional dense vectors (e.g., from 10,000 to 300 dimensions).
Embedding Matrix
An embedding matrix is a trainable matrix in a neural network where each row corresponds to a word’s vector.
Structure:
- Suppose the vocabulary size is
V = 10,000and the embedding size isN = 300. - The embedding matrix
Ewill have shape(V, N).
To retrieve the embedding of word i, simply use:
embedding_vector = E[i]
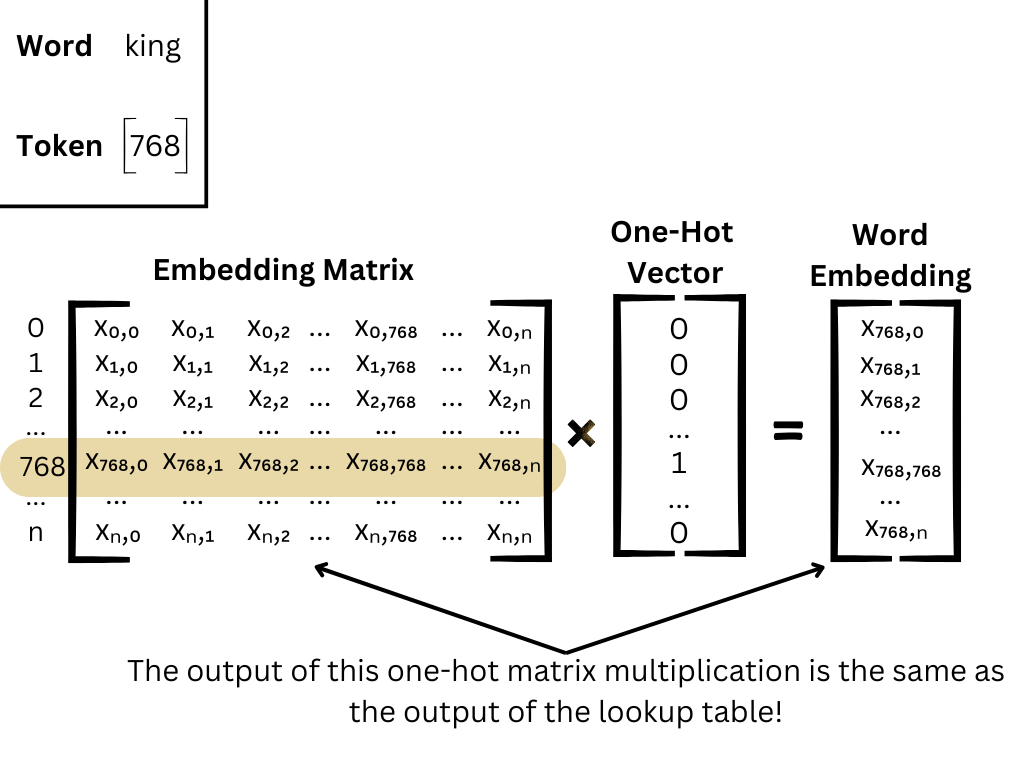
This matrix is updated during training so that embeddings capture task-specific information.
Learning Word Embeddings
Word embeddings can be learned in two ways:
- Supervised Learning: Train a model on a downstream task (e.g., sentiment classification) and update embeddings during training.
- Unsupervised Learning: Train embeddings on large text corpora to learn general-purpose representations (e.g., Word2Vec, GloVe).
Word2Vec
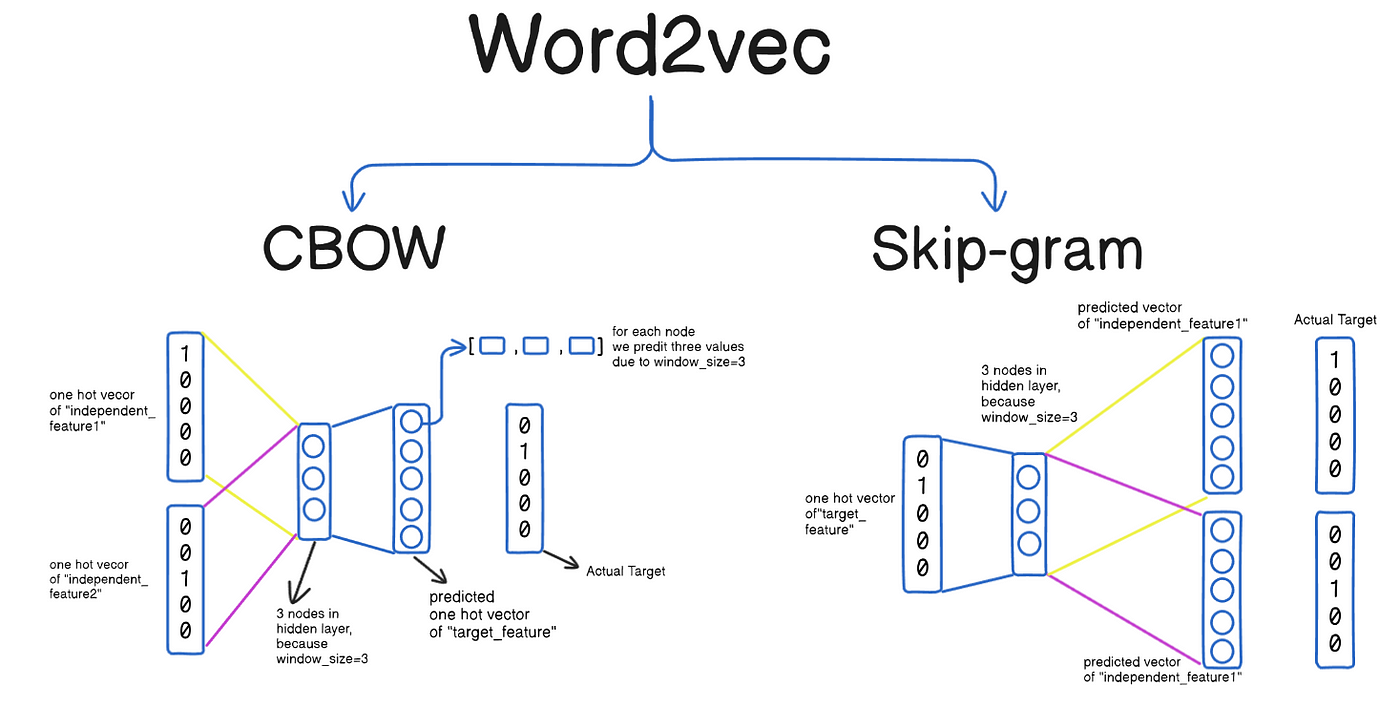
Word2Vec is a popular unsupervised model for learning word embeddings. It has two architectures:
Architectures: CBOW vs Skip-Gram
Word2Vec comes in two main model architectures:
-
Continuous Bag of Words (CBOW):
Predicts the current word based on its context.
Given the surrounding words, the model tries to guess the center word.
Efficient for larger datasets and more frequent words.Example:
- Input: [“the”, “cat”, “on”, “the”, “mat”]
- Center Word: “sat”
- Context: [“the”, “cat”, “on”, “the”, “mat”]
- CBOW tries to predict “sat” from the context.
-
Skip-Gram:
Predicts surrounding context words given the current word.
Given the center word, the model tries to predict the context.
Performs well with smaller datasets and rare words.Example:
- Input: “sat”
- Target Outputs: [“the”, “cat”, “on”, “the”, “mat”]
- Skip-Gram tries to predict the surrounding words from “sat”.
How Word2Vec Learns Word Embeddings
- Word2Vec uses a shallow neural network with one hidden layer.
- The vocabulary size is
V, and the desired vector size isN. - The input layer is a one-hot vector of size
V. - The hidden layer (no activation function) has size
N. - The output layer is also of size
V, predicting a probability distribution over all words.
Steps:
- Convert the input word into a one-hot encoded vector.
- Multiply it by the input weight matrix to get the hidden layer representation.
- Multiply that by the output weight matrix to get scores for all words in the vocabulary.
- Apply softmax to produce a probability distribution.
- Update weights via backpropagation using gradient descent to minimize the loss.
Training Objective: Maximizing Log Probability
For the Skip-Gram model, the goal is to maximize the average log probability:
Where:
- is the total number of words in the corpus.
- is the context window size.
- is the center word, and are the context words.
Computational Challenge: Softmax and Large Vocabulary
Calculating the softmax over a large vocabulary is computationally expensive. To address this, Word2Vec introduces optimization techniques such as:
- Negative Sampling
- Hierarchical Softmax
These methods significantly reduce the training time while maintaining the quality of the learned embeddings.
Example: Learning from a Sentence
Suppose the sentence is:
"The quick brown fox jumps over the lazy dog"
With a context window of size 2, for the center word “brown”, the context is [“The”, “quick”, “fox”, “jumps”].
In the Skip-Gram model, we would train the network to predict each of those context words from “brown”.
Why Word2Vec Works
Word2Vec learns useful representations because:
- It captures both syntactic and semantic relationships.
- It leverages co-occurrence statistics of words in a corpus.
- The vector space preserves many linguistic regularities.
For instance:
vec("Paris") - vec("France") + vec("Italy") ≈ vec("Rome")vec("walking") - vec("walk") + vec("swim") ≈ vec("swimming")
Applications of Word2Vec
- Text classification
- Sentiment analysis
- Named entity recognition
- Question answering
- Semantic search
- Machine translation
These embeddings can be pre-trained (e.g., on Google News) or trained on custom corpora to tailor them to specific domains (e.g., medical texts, legal documents).
Negative Sampling
In Word2Vec, instead of updating weights for all words in the vocabulary, negative sampling updates only a few:
- Pick one positive pair (word and context).
- Sample
knegative words randomly.
This improves efficiency dramatically and allows the model to scale to large corpora.
Loss function (simplified):
Where:
v_wis the input word vectorv_cis the context vectorP_n(w)is the noise distribution
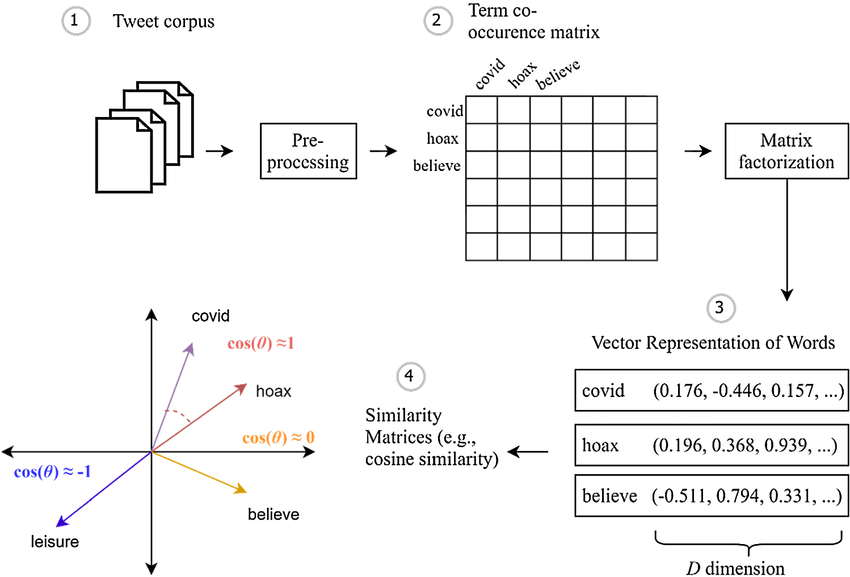
GloVe Word Vectors
GloVe (Global Vectors for Word Representation) is an alternative to Word2Vec. It constructs a co-occurrence matrix X and models the relationships between words based on their global co-occurrence statistics.
Cost function:
Where:
- = number of times word co-occurs with word
- , = word vectors
- , = biases
- = weighting function
This approach captures both local and global word relationships.
Sentiment Classification
Word embeddings can be used as inputs to models like LSTM or CNN for tasks such as sentiment analysis.
Example workflow:
- Convert text to sequence of embeddings.
- Feed sequence into an LSTM.
- Predict a sentiment label: positive, negative, or neutral.
Embeddings help capture contextual sentiment information that traditional methods might miss.
Debiasing Word Embeddings
Word embeddings can reflect and amplify societal biases (e.g., gender bias).
Example:
- vector(“doctor”) might be closer to vector(“man”) than vector(“woman”) in biased embeddings.
Debiasing Techniques:
- Identify bias subspace: e.g., direction of gender (he-she).
- Neutralize: Make gender-neutral words (e.g., “doctor”) orthogonal to the gender direction.
- Equalize: Adjust word pairs (e.g., “man” and “woman”) to be equidistant from neutral terms.
These techniques are essential to make NLP applications fair and inclusive.
This concludes a comprehensive overview of word embeddings and their usage in natural language processing. Each concept here forms the foundation for more advanced NLP models such as Transformers and BERT.