Recurrent Neural Networks (RNNs)
- Why Sequence Models?
- Notation
- Recurrent Neural Network Model
- Backpropagation Through Time
- Different Types of RNNs
- Language Model and Sequence Generation
- Sampling Novel Sequences
- Vanishing Gradients with RNNs
- Gated Recurrent Unit (GRU)
- Long Short-Term Memory (LSTM)
- Bidirectional RNN
- Deep RNNs
Why Sequence Models?
Sequence models are used when the input and/or output is sequential. For example:
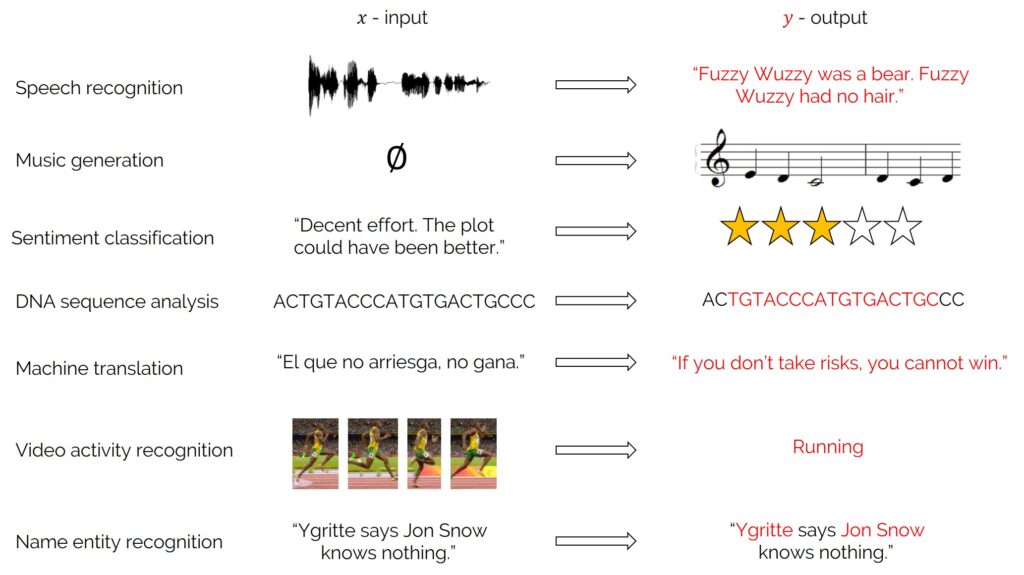
They model dependencies over time or sequence positions, which standard feedforward neural networks cannot do efficiently.
Notation
- : input at time step
- : output at time step
- : hidden state at time step
- : predicted output at time step
- : sequence length
Recurrent Neural Network Model
The RNN computes:
RNNs share parameters across time, allowing generalization to different sequence lengths.
Backpropagation Through Time
To train RNNs, we use backpropagation through time (BPTT):
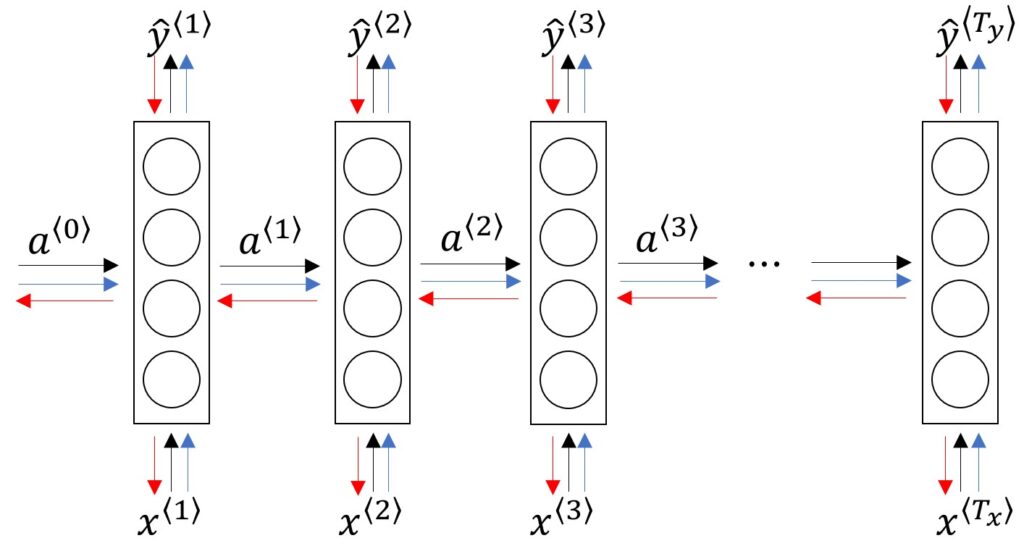
- Unroll the RNN for steps
- Compute loss and gradients across all time steps
- Apply chain rule for gradients through time dependencies
Different Types of RNNs
- Many-to-Many: sequence input and sequence output (e.g., machine translation)
- Many-to-One: sequence input, single output (e.g., sentiment analysis)
- One-to-Many: single input, sequence output (e.g., image captioning)
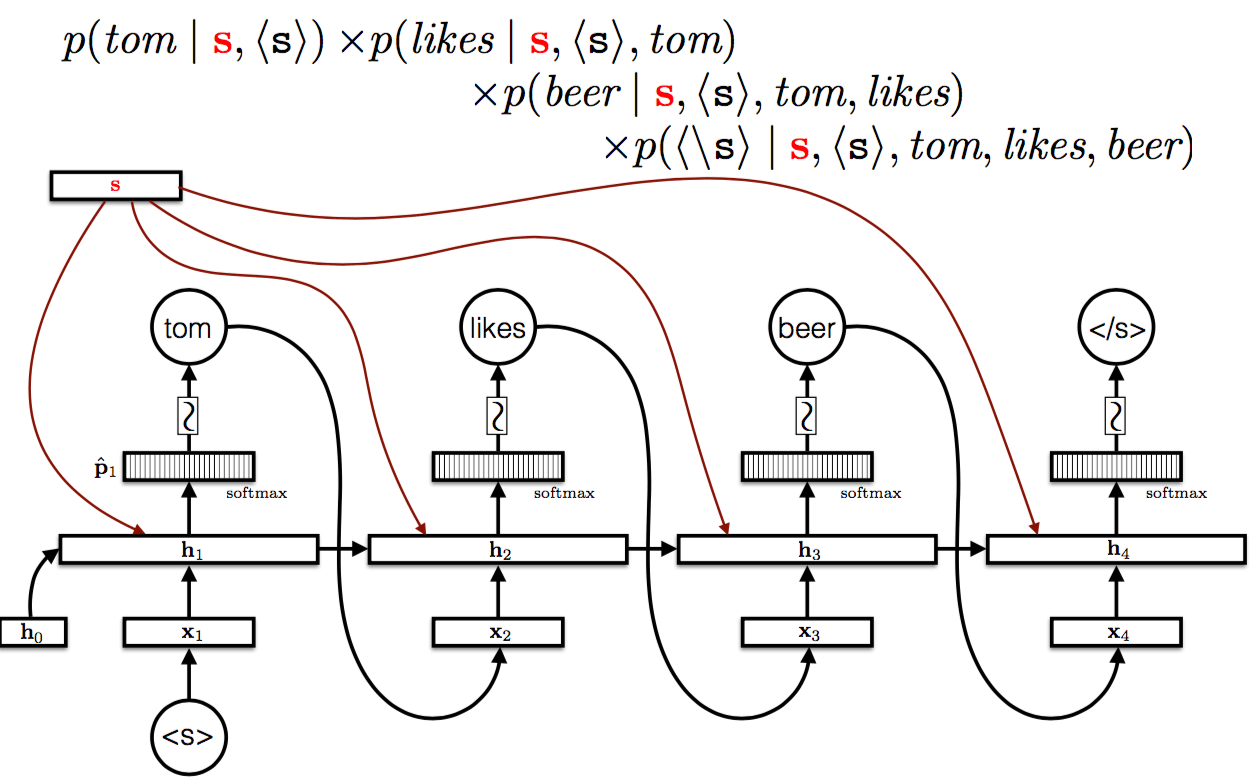
Language Model and Sequence Generation
Language models predict the next word given a sequence:
Training: minimize cross-entropy loss between predicted and actual next words.
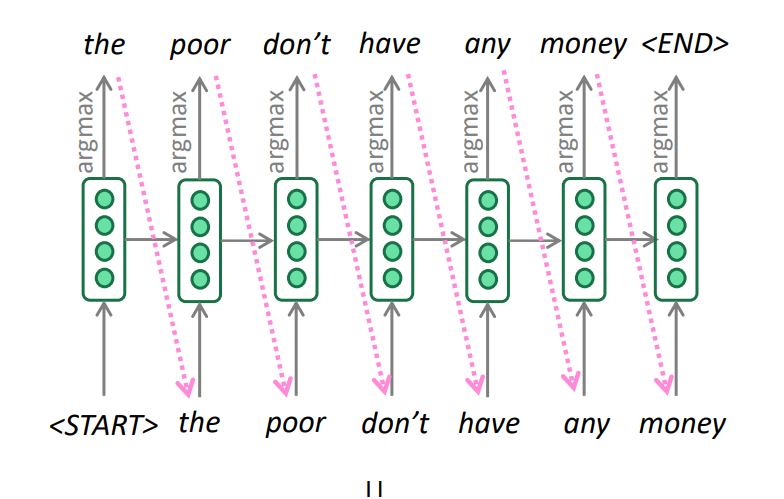
Sampling Novel Sequences
- Start with a seed (e.g.,
) - Sample , feed it back
- Continue until
or max length
Sampling temperature can control randomness:
- Low temperature = conservative (likely choices)
- High temperature = creative (diverse outputs)
Vanishing Gradients with RNNs
One of the fundamental challenges in training RNNs is the vanishing gradient problem, especially when modeling long-term dependencies.
When computing gradients using Backpropagation Through Time (BPTT), the gradients at earlier time steps are affected by the repeated multiplication of small values (from derivatives of activation functions like tanh or sigmoid). This leads to:
- Gradients becoming very small (vanish): weights are barely updated for earlier time steps
- Gradients becoming very large (explode): instability and divergence in training
Intuition with Example:
Consider a sequence: “I grew up in France… I speak fluent ___”
The model needs to learn that the word “French” depends on the context word “France” seen many time steps earlier. If the gradient shrinks too much over those steps, the model fails to learn this dependency.
Consequences:
- Short-term dependencies are learned effectively.
- Long-term dependencies are often lost.
Gated Recurrent Unit (GRU)
Why do we need GRUs?
Traditional RNNs struggle with learning long-term dependencies due to the vanishing gradient problem. As sequences grow longer, the gradients used during backpropagation either shrink or explode, making it hard for the network to retain information over time.
GRUs are designed to solve this by introducing gating mechanisms that control what information should be remembered, updated, or forgotten. These gates make the network more efficient at learning dependencies in long sequences.
GRU introduces gates to control information flow:
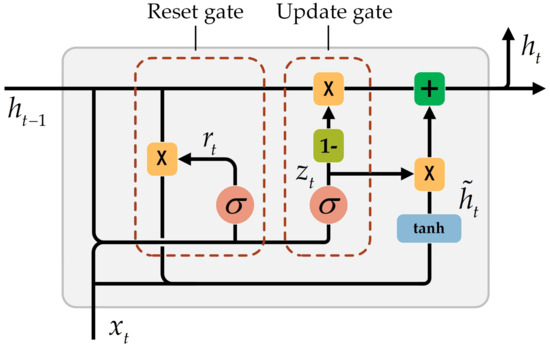
A GRU has two main gates:
-
Update Gate ():
-
Determines how much of the previous memory to keep.
-
If z ≈ 1, it keeps the old memory.
-
If z ≈ 0, it updates with new information.
-
-
Reset Gate ():
-
Controls how much of the previous state should be ignored.
-
Helps in deciding whether to forget the old state when generating the new memory.
-
Equations:
GRU vs Traditional RNN
| Feature | RNN | GRU |
|---|---|---|
| Memory control | None | Yes (update/reset gates) |
| Vanishing gradients | Common | Less frequent |
| Parameter efficiency | Fewer params | More, but fewer than LSTM |
| Training speed | Fast | Slower than RNN, faster than LSTM |
Example: Sequence with Context
Imagine trying to classify the sentiment of the sentence:
“The movie was terrible… but the ending was amazing.”
- A vanilla RNN might forget the earlier “terrible” and overly weight the “amazing”, resulting in an incorrect positive classification.
- A GRU, however, can learn to retain both sentiments and give a more balanced representation by preserving long-term context.
Long Short-Term Memory (LSTM)
Why Do We Need LSTM?
Traditional RNNs struggle with long-term dependencies due to vanishing gradients, which hinder learning over long sequences.
To solve this, LSTMs introduce memory cells and gates that help preserve and regulate information across time steps.
LSTM Architecture Intuition
LSTM cells introduce three gates to control information:
- Forget Gate: Decides what information to throw away from the cell state.
- Input Gate: Decides which new information should be stored in the cell state.
- Output Gate: Decides what to output based on the cell state.
This gating mechanism allows the model to retain relevant information over long durations while discarding unnecessary data.
LSTM Cell: Step-by-Step
Let’s break down an LSTM cell computation for a single time step . Let:
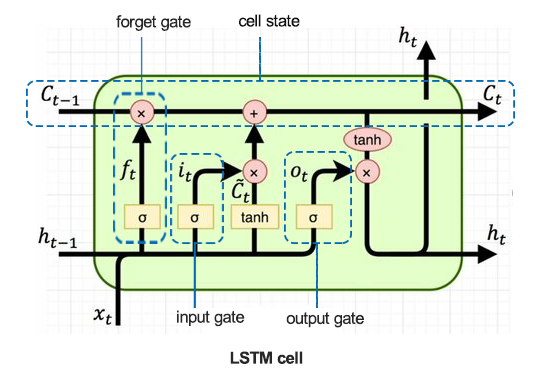
- : input at time
- : hidden state from previous step
- : cell state from previous step
Then, the LSTM performs the following operations:
-
Forget Gate :
Decides what to forget from the previous cell state.
-
Input Gate and Candidate Values :
Determines what new information to add to the cell state.
-
Update Cell State:
-
Output Gate and Hidden State :
Example: Comparing RNN and LSTM
Suppose we want to predict the next word in a sentence. Let’s compare:
RNN:
- Struggles to maintain context when sentences are long.
- For example:
"The cat, which was chased by the dog, ran up the..." → "tree"→ the subject “cat” may be forgotten.
LSTM:
- Maintains the context of “the cat” and successfully predicts
"tree".
| Feature | RNN | LSTM |
|---|---|---|
| Handles Long-Term Dependencies | ❌ | ✅ |
| Vanishing Gradient Resistant | ❌ | ✅ |
| Uses Gates | ❌ | ✅ (Forget, Input, Output) |
| Computational Complexity | Low | Higher, but more expressive |
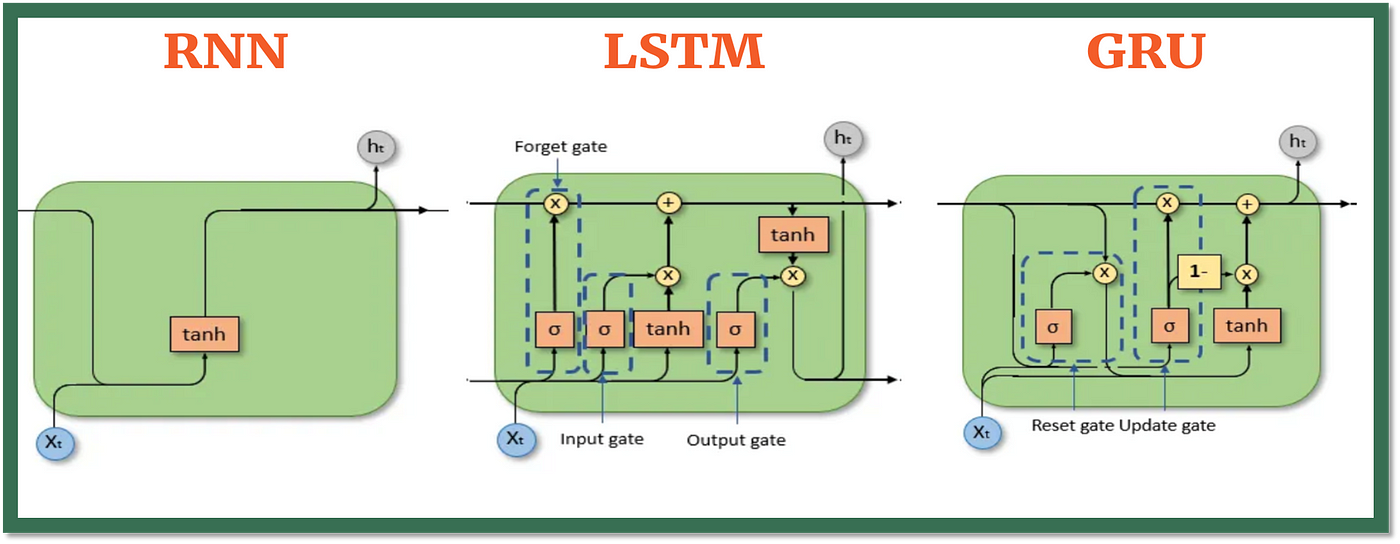
LSTMs are widely used in natural language processing, speech recognition, time series forecasting, and anywhere long-term memory is crucial.
Bidirectional RNN
In a standard RNN, information flows in a single direction — typically from past to future. However, in many tasks (like speech recognition or named entity recognition), context from both past and future words is useful for understanding the current input. This is where Bidirectional RNNs (BiRNNs) come in.
Why Use Bidirectional RNNs?
A Bidirectional RNN processes the input sequence in both directions with two separate hidden layers:
- One moves forward through time (from to )
- One moves backward through time (from to )
The outputs of both directions are concatenated at each time step:
- Access to future context: Helps the model make better predictions at each time step.
- Improved performance: Especially effective in tasks where the meaning of a word depends on both previous and next words.
Imagine the sentence:
“He said he saw a bat.”
If we only process the sentence from left to right, the meaning of the word “bat” is unclear until we see the following context. A Bidirectional RNN can process both directions and better disambiguate the meaning using the full sentence context.
Applications
- Named Entity Recognition (NER)
- Part-of-Speech (POS) tagging
- Speech recognition
- Text classification
Bidirectional RNNs are often used with LSTM or GRU units to capture long-term dependencies more effectively in both directions.
Deep RNNs
Deep RNNs consist of stacking multiple recurrent layers on top of each other, allowing the network to learn hierarchical representations of sequences. By increasing the depth, the model can capture more complex temporal patterns and abstractions.
- Each layer’s output serves as input to the next recurrent layer.
- Enables learning of higher-level features across time steps.
- Can improve model capacity and expressiveness.
Challenges:
- Increased risk of overfitting due to more parameters.
- Training can be slower and more difficult due to vanishing/exploding gradients.
Applications:
- Complex sequence modeling tasks such as speech recognition, language modeling, and video analysis.
Deep RNNs are often combined with advanced units like LSTM or GRU to mitigate training difficulties and capture long-term dependencies effectively.