- Introduction to Gradient Descent
- Mathematical Formulation of Gradient Descent
- Learning Rate ()
- Gradient Descent Convergence
- Local Minimum vs Global Minimum
Introduction to Gradient Descent
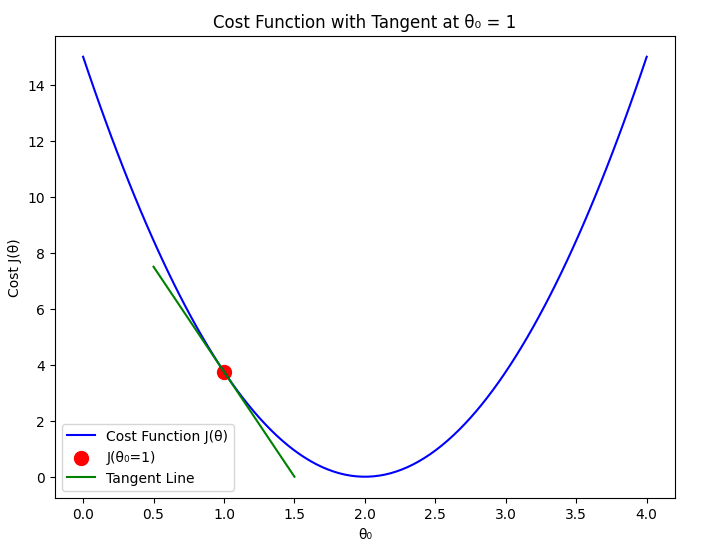
In the previous section, we explored how the cost function behaves when assuming different values of with (To visualize it easily, we give zero to ). Now, we introduce Gradient Descent, an optimization algorithm used to find the best parameters that minimize the cost function .
our hypothesis function simplifies to:
Gradient Descent is an iterative method that updates the parameter step by step in the direction that reduces the cost function. The algorithm helps us find the optimal value of efficiently instead of manually testing different values.
To understand how Gradient Descent works, let’s recall our dataset:
| x values | y values |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| 4 | 8 |
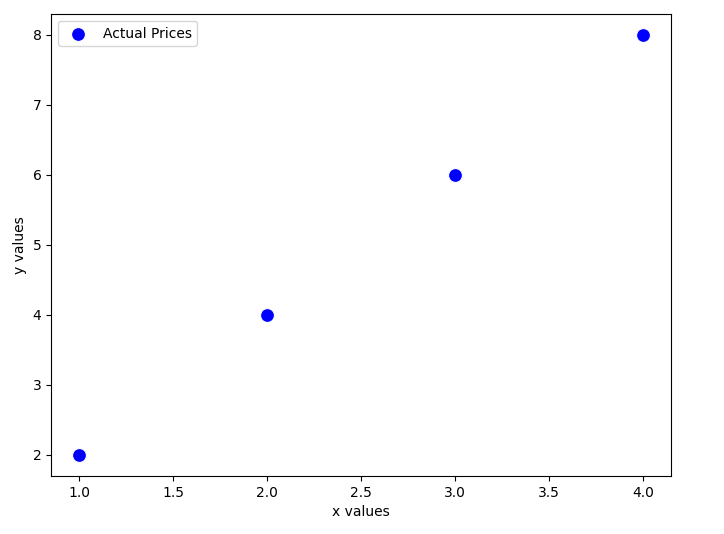
We aim to find the best value of that minimizes the error between our predictions and the actual values. Gradient Descent will iteratively adjust to reach the minimum cost.
Mathematical Formulation of Gradient Descent
Gradient Descent is an optimization algorithm used to minimize a function by iteratively updating its parameters in the direction of the steepest descent. In our case, we aim to minimize the cost function:
Where:
- 𝑚 is the number of training examples.
- represents our hypothesis function (predicted values).
- y represents the actual target values.
- Goal: Find the optimal that minimizes .
1. Gradient Descent Update Rule
Gradient Descent uses the derivative of the cost function to determine the direction and magnitude of updates. The general update rule for is:
Where:
- (learning rate) controls the step size of updates.
- is the gradient (derivative) of the cost function with respect to .
Why Do We Use the Derivative?
The derivative tells us the slope of the cost function. If the slope is positive, we need to decrease , and if it is negative, we need to increase , guiding us toward the minimum of . Without derivatives, we wouldn’t know which direction to move to minimize the function.
The gradient tells us how steeply the function increases or decreases at a given point.
- If the gradient is positive, is decreased.
- If the gradient is negative, is increased.
This ensures that we move toward the minimum of the cost function.
2. Computing the Gradient
First, recall our hypothesis function:
Now, we compute the derivative of the cost function:
This expression represents the average gradient of the errors multiplied by the input values. Using this gradient, we update in each iteration:
- If the error is large, the update step is bigger.
- If the error is small, the update step is smaller.
This way, the algorithm gradually moves towards the optimal .
Learning Rate ()
The learning rate is a crucial parameter in the gradient descent algorithm. It determines how large a step we take in the direction of the negative gradient during each iteration. Choosing an appropriate learning rate is essential for ensuring efficient convergence of the algorithm.
If the learning rate is too small, the algorithm will take tiny steps towards the minimum, leading to slow convergence. On the other hand, if the learning rate is too large, the algorithm may overshoot the minimum or even diverge, never reaching an optimal solution.
1. When is Too Small
If the learning rate is set too small:
- Gradient descent will take very small steps in each iteration.
- Convergence to the minimum cost will be extremely slow.
- It may take a large number of iterations to reach a useful solution.
- The algorithm might get stuck in local variations of the cost function, slowing down learning.
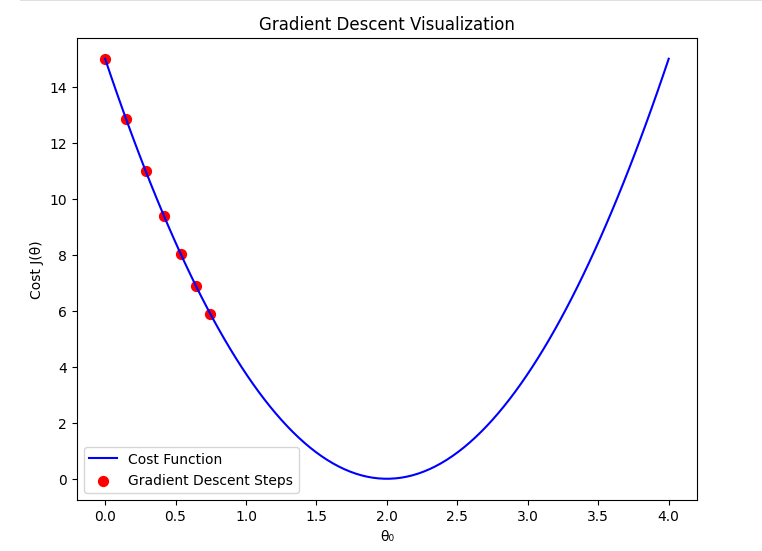
Mathematically, the update rule is: When is very small, the change in per step is minimal, making the process inefficient.
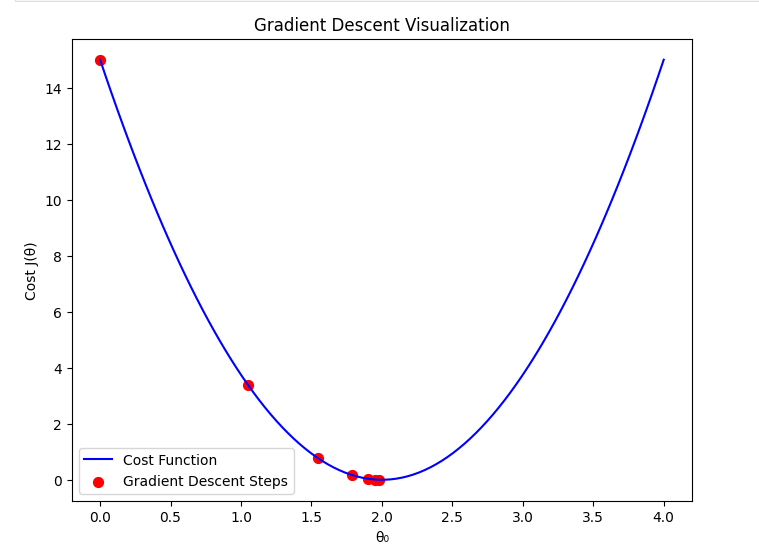
2. When is Optimal
If the learning rate is chosen optimally:
- The gradient descent algorithm moves efficiently towards the minimum.
- It balances speed and stability, converging in a reasonable number of iterations.
- The cost function decreases steadily without oscillations or divergence.
A well-chosen ensures that gradient descent follows a smooth and steady path to the minimum.
3. When is Too Large
If the learning rate is set too large:
- Gradient descent may take excessively large steps.
- Instead of converging, it may oscillate around the minimum or diverge entirely.
- The cost function might increase instead of decreasing due to overshooting the optimal .
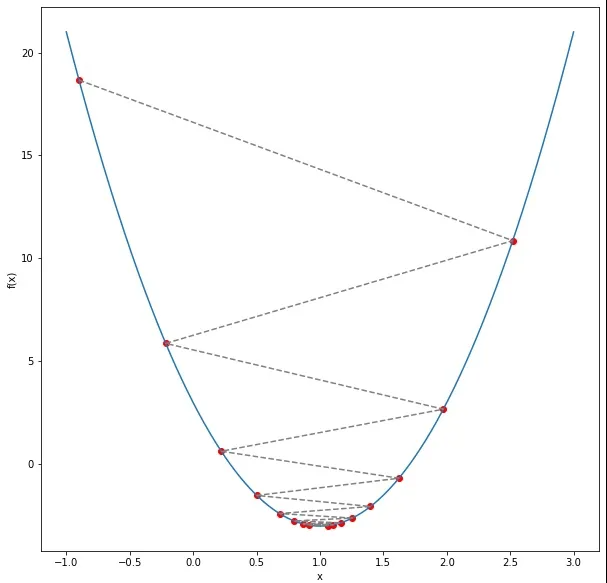
In extreme cases, the cost function values might increase indefinitely, causing the algorithm to fail to find a minimum.
Summary
Selecting the right learning rate is essential for gradient descent to work efficiently. A well-balanced ensures that the algorithm converges quickly and effectively. In the next section, we will implement gradient descent with different learning rates to visualize their effects.
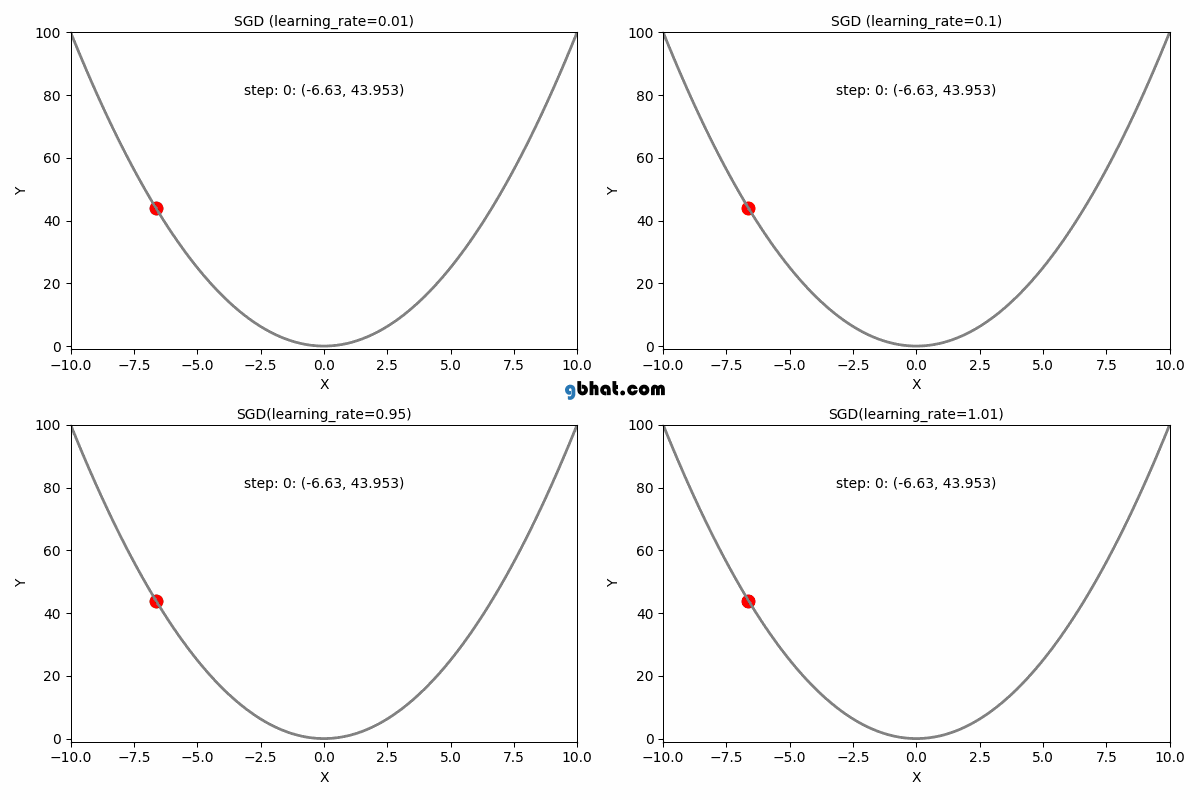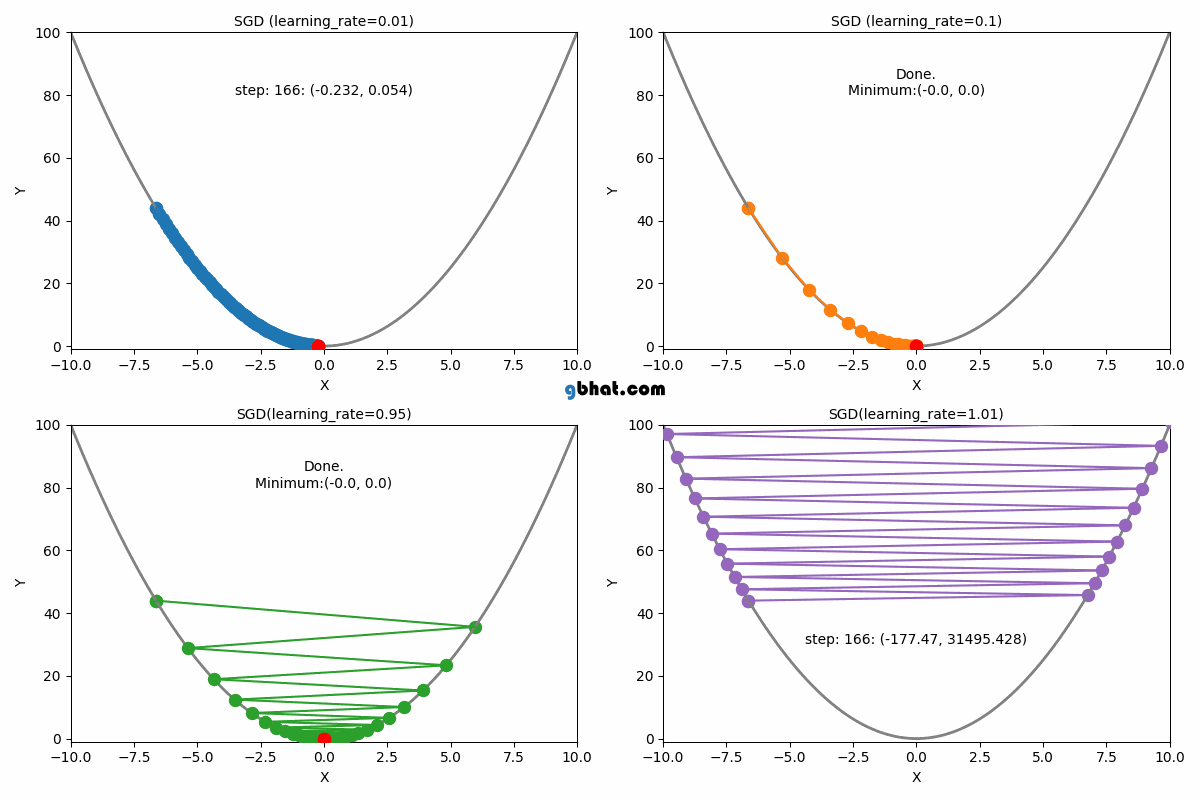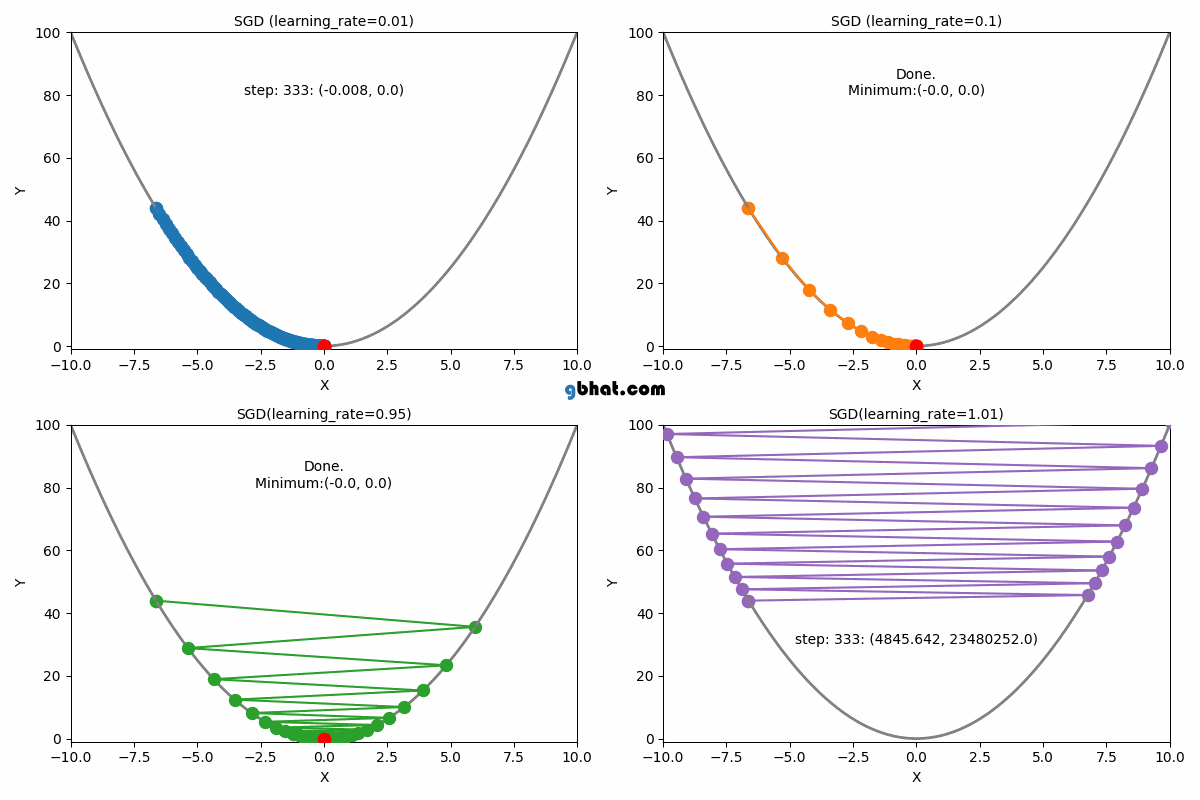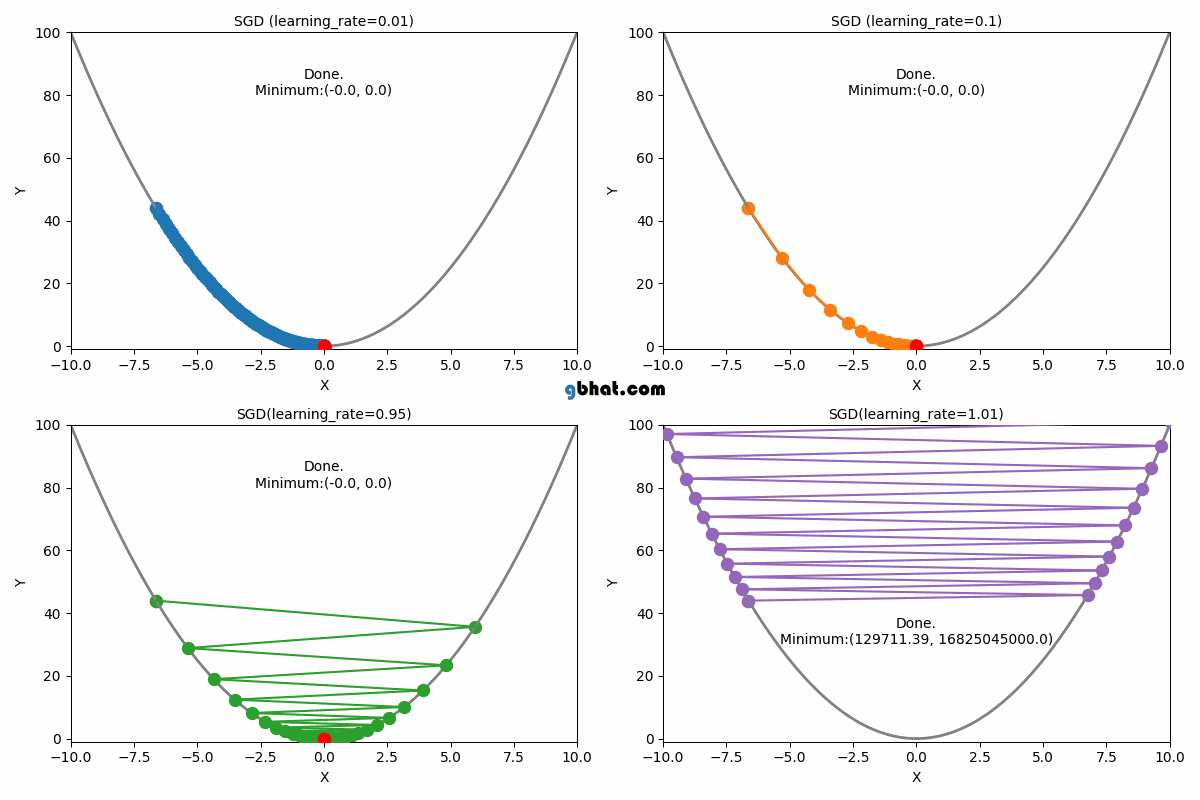
Gradient Descent Convergence
Gradient Descent is an iterative optimization algorithm that minimizes the cost function, J(\theta), by updating parameters step by step. However, we need a proper stopping criterion to determine when the algorithm has converged.
1. Convergence Criteria
The algorithm should stop when one of the following conditions is met:
- Small Gradient: If the derivative (gradient) of the cost function is close to zero, meaning the algorithm is near the optimal point.
- Minimal Cost Change: If the difference in the cost function between iterations is below a predefined threshold ().
- Maximum Iterations: A fixed number of iterations is reached to avoid infinite loops.
2. Choosing the Right Stopping Condition
- Stopping Too Early: If the algorithm stops before reaching the optimal solution, the model may not perform well.
- Stopping Too Late: Running too many iterations may waste computational resources without significant improvement.
- Optimal Stopping: The best condition is when further updates do not significantly change the cost function or parameters.
Local Minimum vs Global Minimum
Understanding the Concept
When optimizing a function, we aim to find the point where the function reaches its lowest value. This is crucial in machine learning because we want to minimize the cost function effectively. However, there are two types of minima that gradient descent might encounter:
- Global Minimum: The absolute lowest point of the function. Ideally, gradient descent should converge here.
- Local Minimum: A point where the function has a lower value than nearby points but is not the absolute lowest value.
For convex functions (such as our quadratic cost function), gradient descent is guaranteed to reach the global minimum. However, for non-convex functions, the algorithm may get stuck in a local minimum.
Convex vs Non-Convex Cost Functions
- Convex Functions
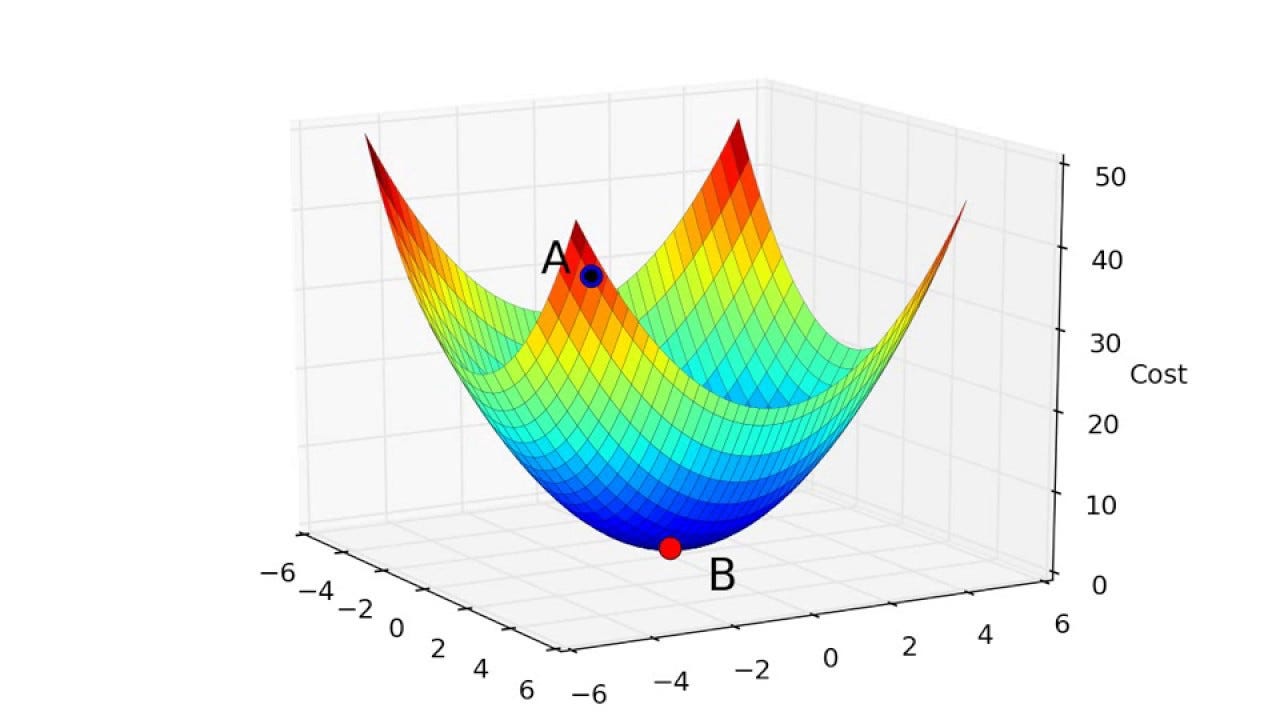
- The cost function is convex for linear regression.
- This ensures that gradient descent always leads to the global minimum.
- Example: A simple quadratic function like .
- Non-Convex Functions
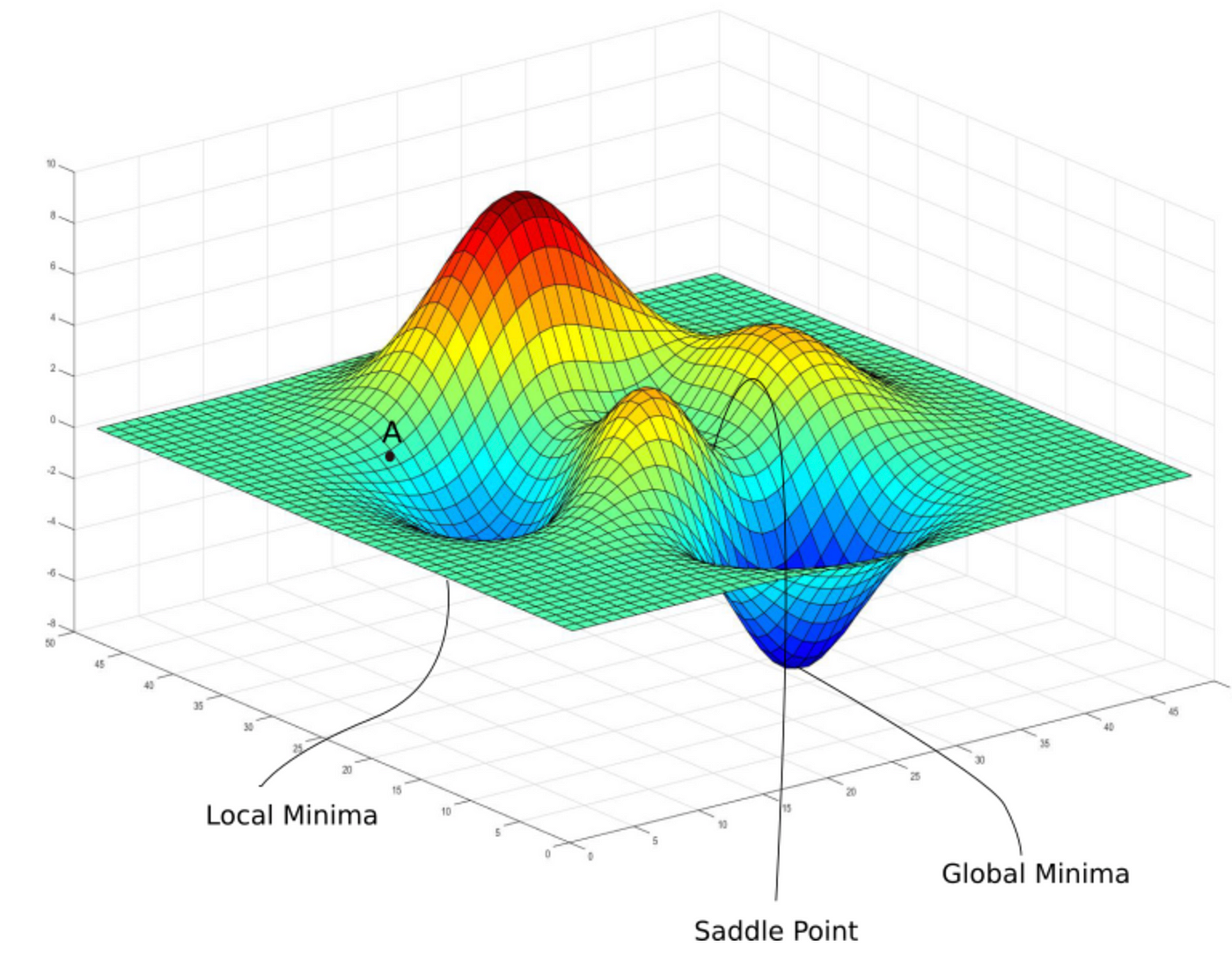
- More common in deep learning and complex machine learning models.
- There can be multiple local minima.
- Example: Functions with multiple peaks and valleys, such as .