Classic Networks: LeNet-5, AlexNet, VGG
- Why Look at Classic Networks?
- LeNet-5 (1998, Yann LeCun)
- AlexNet (2012, Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton)
- VGG Networks (2014, Visual Geometry Group, Oxford)
- Summary Table
- Final Thoughts
In the early stages of deep learning and computer vision, several foundational convolutional neural network (CNN) architectures shaped the field and enabled significant breakthroughs in image recognition. In this document, we explore three of the most historically significant and technically influential networks: LeNet-5, AlexNet, and VGG.
These architectures demonstrate the progression of CNN design from shallow, simple models to deeper, more powerful systems capable of scaling to large datasets like ImageNet.
Why Look at Classic Networks?
Understanding classic CNN architectures is essential for the following reasons:
- They introduce fundamental building blocks (e.g., convolutional layers, pooling layers, ReLU activation).
- They highlight challenges faced at different stages of deep learning evolution (e.g., overfitting, vanishing gradients).
- They provide insights into the design philosophy of modern deep architectures.
LeNet-5 (1998, Yann LeCun)
Overview
LeNet-5 was one of the earliest CNN models designed to recognize handwritten digits (e.g., MNIST dataset). It demonstrated the power of learned convolutional filters combined with a small number of parameters.
Architecture
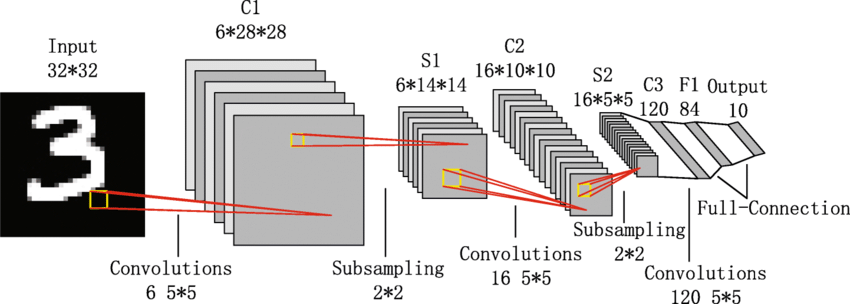
- Input: 32x32 grayscale image
- C1: Convolutional layer with 6 filters of size 5x5 → output: 28x28x6
- S2: Subsampling (average pooling) layer → output: 14x14x6
- C3: Convolutional layer with 16 filters → output: 10x10x16
- S4: Subsampling layer → output: 5x5x16
- C5: Fully connected convolutional layer → output: 120
- F6: Fully connected layer → output: 84
- Output: 10-class softmax layer
Parameters
LeNet uses shared weights, reducing the number of parameters compared to fully connected networks.
Insights
- Introduced the idea of local receptive fields, weight sharing, and subsampling.
- Excellent for small datasets but struggles with large-scale data due to its shallow depth.
AlexNet (2012, Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton)
Breakthrough
AlexNet marked the first major success of deep learning in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC 2012), achieving top-5 error of 15.3%, compared to 26% for the runner-up.
Architecture
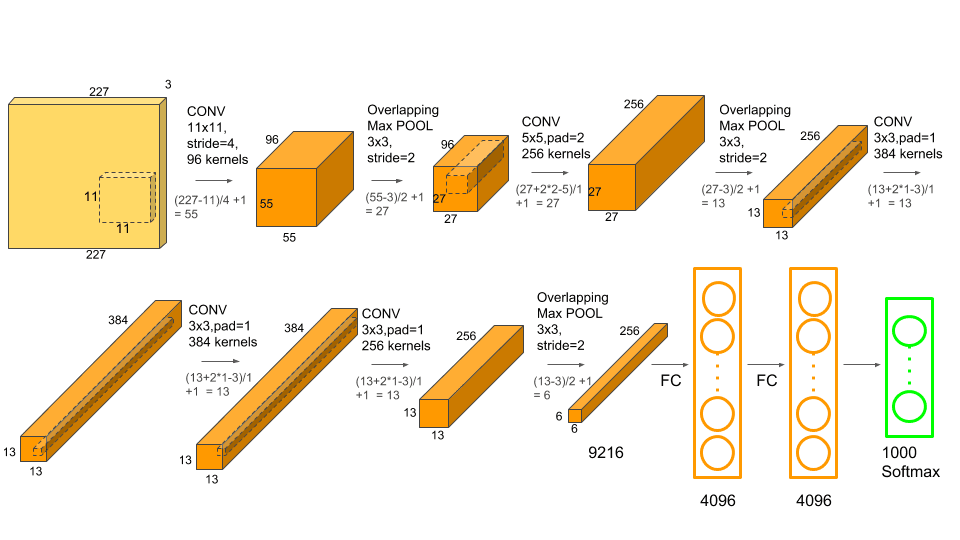
- Input: 224x224x3 RGB image
- Conv1: 96 filters of 11x11, stride 4 → 55x55x96
- MaxPool1: 3x3, stride 2 → 27x27x96
- Conv2: 256 filters of 5x5 → 27x27x256
- MaxPool2: 3x3 → 13x13x256
- Conv3: 384 filters of 3x3 → 13x13x384
- Conv4: 384 filters of 3x3 → 13x13x384
- Conv5: 256 filters of 3x3 → 13x13x256
- MaxPool3: 3x3 → 6x6x256
- FC6: Fully connected layer with 4096 neurons
- FC7: Fully connected layer with 4096 neurons
- FC8: 1000-way softmax layer
Key Innovations
- Used ReLU (Rectified Linear Unit) instead of sigmoid or tanh → faster training
- Introduced dropout for regularization
- Trained on two GPUs in parallel
Insights
- Showed the world that deep networks could outperform traditional machine learning models if trained with large datasets and GPUs.
VGG Networks (2014, Visual Geometry Group, Oxford)
VGG emphasized simplicity and depth: using small 3x3 filters and stacking them deeply to capture complex patterns.
Architecture (VGG-16)
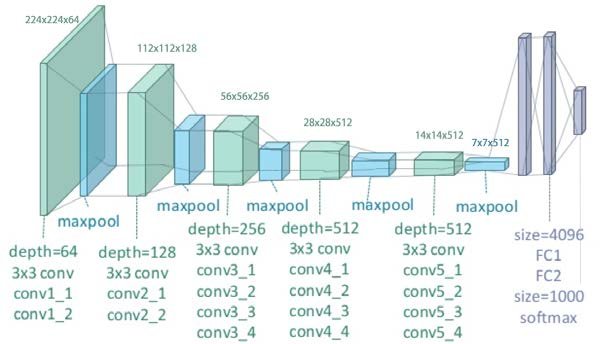
- Input: 224x224x3 RGB image
- Stack of 13 convolutional layers using 3x3 filters
- 5 max-pooling layers to reduce spatial dimensions
- 3 fully connected layers, with the last one as a softmax for classification
Example:
- Conv3-64 → Conv3-64 → MaxPool
- Conv3-128 → Conv3-128 → MaxPool
- Conv3-256 → Conv3-256 → Conv3-256 → MaxPool
- Conv3-512 → Conv3-512 → Conv3-512 → MaxPool
- Conv3-512 → Conv3-512 → Conv3-512 → MaxPool
- FC-4096 → FC-4096 → Softmax(1000)
Characteristics
- Consistent use of 3x3 filters simplifies the design and enables deeper networks
- Requires significant memory and computation (hundreds of millions of parameters)
Insights
- Demonstrated that depth is a key factor in improving CNN performance
- The architecture became a benchmark and inspired many follow-up models
Summary Table
| Model | Year | Input Size | Depth | Unique Aspects |
|---|---|---|---|---|
| LeNet-5 | 1998 | 32x32 | 7 | Local receptive fields, subsampling |
| AlexNet | 2012 | 224x224x3 | 8 | ReLU, dropout, GPU parallelism |
| VGG-16 | 2014 | 224x224x3 | 16 | Simplicity, 3x3 filters, depth |
Final Thoughts
These classic CNN architectures form the backbone of modern computer vision systems. Each contributed key architectural innovations that addressed specific challenges in training deep networks.
Understanding them allows us to appreciate the evolution of deep learning and to better design models suited for today’s massive data and compute resources.