Overfitting and Regularization
- 1. The Problem of Overfitting
- 2. Addressing Overfitting
- 3. Regularized Cost Function
- 4. Regularized Linear Regression
- 5. Regularized Logistic Regression
1. The Problem of Overfitting
What is Overfitting?
Overfitting occurs when a machine learning model learns the training data too well, capturing noise and random fluctuations rather than the underlying pattern. As a result, the model performs well on training data but generalizes poorly to unseen data.
Symptoms of Overfitting
- High training accuracy but low test accuracy (poor generalization).
- Complex decision boundaries that fit training data too closely.
- Large model parameters (high magnitude weights), leading to excessive sensitivity to small changes in input data.
Example of Overfitting in Regression
Consider a polynomial regression model. If we fit a high-degree polynomial to data, the model may pass through all training points perfectly but fail to predict new data correctly.
Overfitting vs. Underfitting
| Model Complexity | Training Error | Test Error | Generalization |
|---|---|---|---|
| Underfitting (High Bias) | High | High | Poor |
| Good Fit | Low | Low | Good |
| Overfitting (High Variance) | Very Low | High | Poor |
Visualization of Overfitting
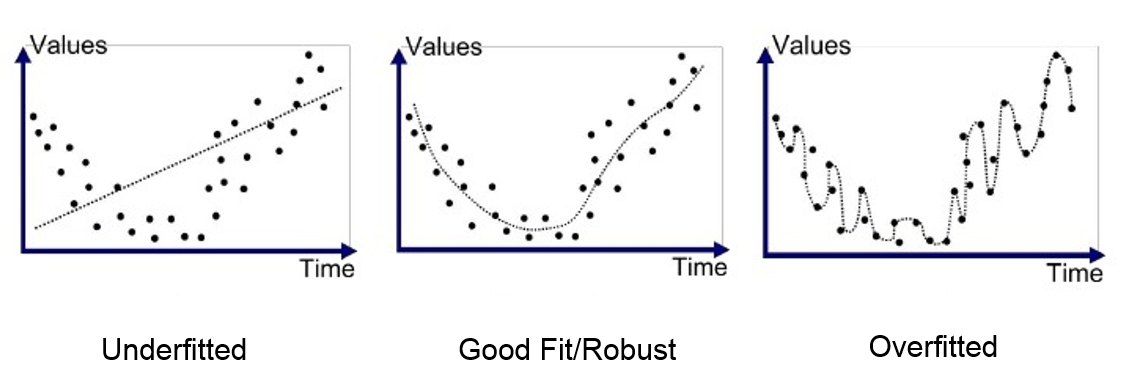
- Left (Underfitting): The model is too simple and cannot capture the trend.
- Middle (Good Fit): The model captures the pattern without overcomplicating.
- Right (Overfitting): The model follows the training data too closely, failing on new inputs.
2. Addressing Overfitting
Overfitting occurs when a model learns noise instead of the underlying pattern in the data. To address overfitting, we can apply several strategies to improve the model’s ability to generalize to unseen data.
1. Collecting More Data
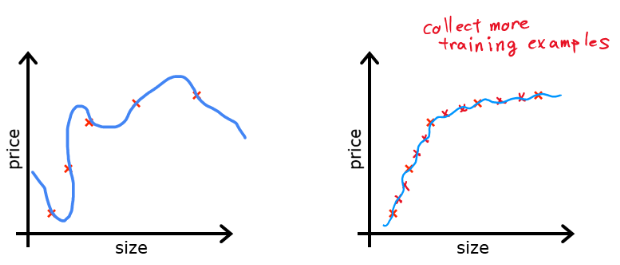
- More training data helps the model capture real patterns rather than memorizing noise.
- Especially effective for deep learning models, where small datasets tend to overfit quickly.
- Not always feasible, but can be supplemented with data augmentation techniques.
2. Feature Selection & Engineering
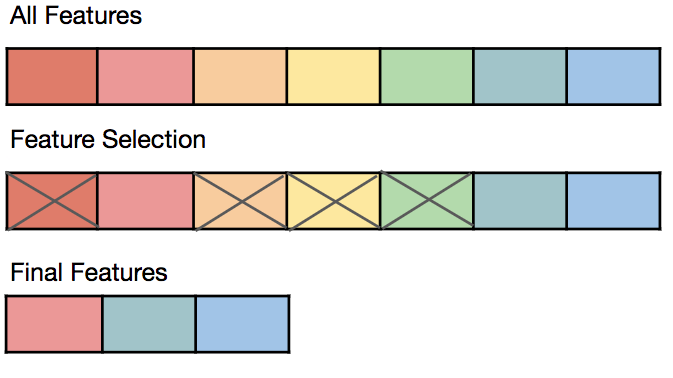
- Removing irrelevant or redundant features reduces model complexity.
- Techniques like Principal Component Analysis (PCA) help reduce dimensionality.
- Engineering new features (e.g., creating polynomial features or interaction terms) can improve generalization.
3. Cross-Validation
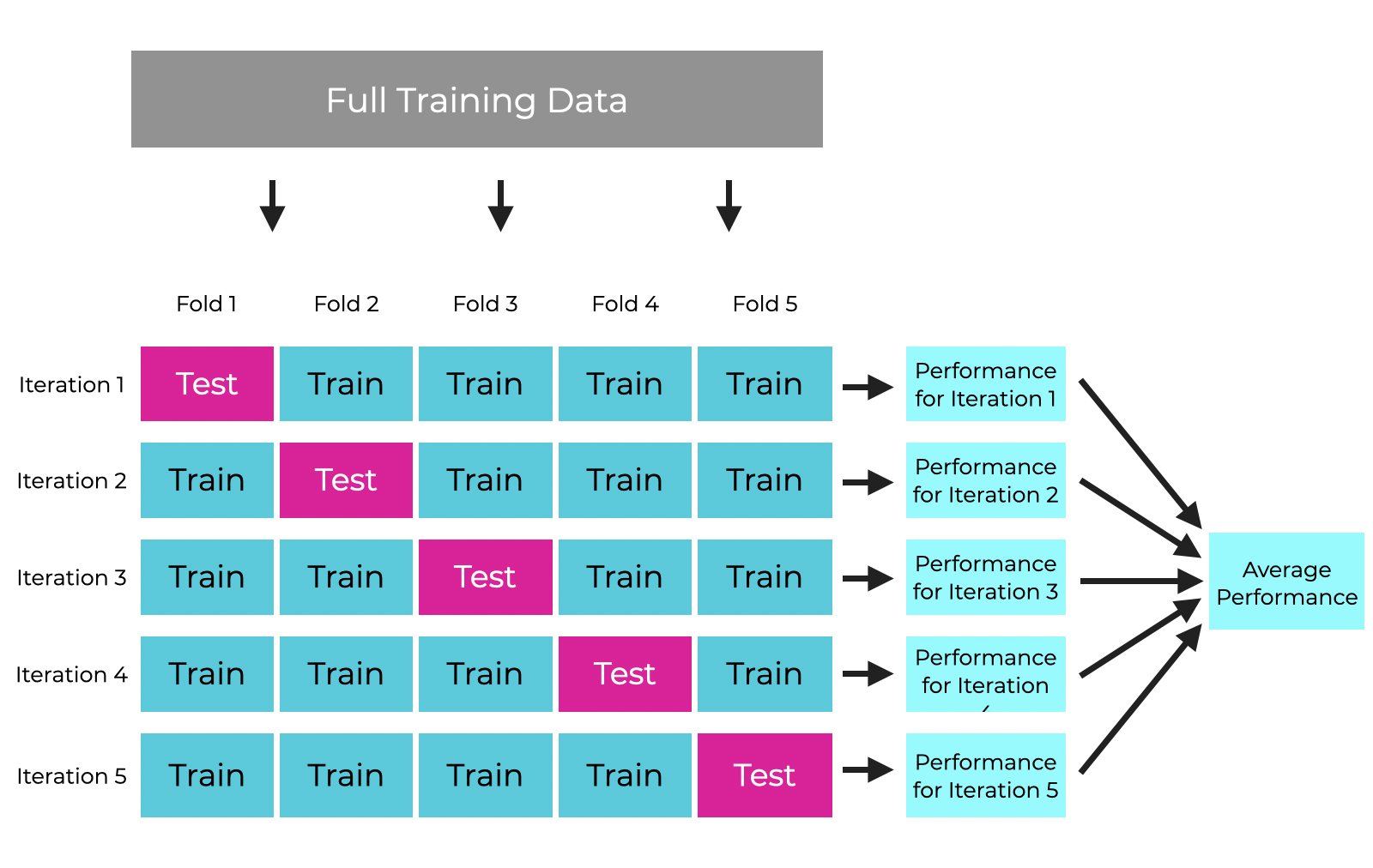
- k-fold cross-validation ensures that the model performs well on different data splits.
- Helps detect overfitting early by testing the model on multiple subsets of data.
- Leave-one-out cross-validation (LOOCV) is another approach, especially useful for small datasets.
4. Regularization as a Solution
- Regularization techniques add constraints to the model to prevent excessive complexity.
- L1 (Lasso) and L2 (Ridge) Regularization introduce penalties for large coefficients.
- We will explore regularized cost functions in the next section.
By applying these techniques, we control model complexity and improve generalization performance. In the next section, we will dive deeper into regularization and its role in the cost function.
3. Regularized Cost Function
Overfitting often occurs when a model learns excessive complexity, leading to poor generalization. One way to control this is by modifying the cost function to penalize overly complex models.
1. Why Modify the Cost Function?
The standard cost function in regression or classification only minimizes the error on training data, which can result in large coefficients (weights) that overfit the data.
By adding a regularization term, we discourage large weights, making the model simpler and reducing overfitting.
2. Adding Regularization Term
Regularization adds a penalty term to the cost function that shrinks the model parameters. The two most common types of regularization are:
L2 Regularization (Ridge Regression)
In L2 regularization, we add the sum of squared weights to the cost function:
- (regularization parameter) controls how much regularization is applied.
- Higher values force the model to reduce the magnitude of parameters, preventing overfitting.
- L2 regularization keeps all features but reduces their impact.
L1 Regularization (Lasso Regression)
In L1 regularization, we add the absolute values of weights:
- L1 regularization pushes some coefficients to zero, effectively performing feature selection.
- It results in sparser models, which are useful when many features are irrelevant.
3. Effect of Regularization on Model Complexity
Regularization controls model complexity by restricting parameter values:
- No Regularization () → The model fits the training data too closely (overfitting).
- Small → The model is still flexible but generalizes better.
- Large → The model becomes too simple (underfitting), losing important patterns.
Visualization of Regularization Effects

- Left (No Regularization): The model overfits training data.
- Middle (Moderate Regularization): The model generalizes well.
- Right (Strong Regularization): The model underfits the data.
4. Regularized Linear Regression
Linear regression without regularization can suffer from overfitting, especially when the model has too many features or when training data is limited. Regularization helps by constraining the model’s parameters, preventing extreme values that lead to high variance.
1. Linear Regression Cost Function (Without Regularization)
The standard cost function for linear regression is:
where:
- is the hypothesis (predicted value),
- is the number of training examples.
This function minimizes the sum of squared errors but does not impose any restrictions on the parameter values, which can lead to overfitting.
2. Regularized Cost Function for Linear Regression
To prevent overfitting, we add an L2 regularization term (also known as Ridge Regression) to penalize large parameter values:
where:
- is the regularization parameter that controls the penalty,
- The term penalizes large values of ,
- (bias term) is not regularized.
3. Effect of Regularization in Gradient Descent
Regularization modifies the gradient descent update rule:
- The additional term shrinks the parameter values over time.
- When is too large, the model underfits (too simple).
- When is too small, the model overfits (too complex).
Effect of Regularization on Parameters
- If : Regularization is off → Overfitting risk.
- If is too high: Model is too simple → Underfitting.
- If is optimal: Good generalization → Balanced model.
4. Normal Equation with Regularization
For linear regression, we can solve for using the Normal Equation, which avoids gradient descent:
where:
- is the identity matrix (except is not regularized).
- Adding ensures is invertible, reducing multicollinearity issues.
5. Summary
✅ Regularization reduces overfitting by penalizing large weights.
✅ L2 regularization (Ridge Regression) modifies cost function by adding .
✅ Gradient Descent and Normal Equation both adjust to include regularization.
✅ Choosing is critical: too high → underfitting, too low → overfitting.
5. Regularized Logistic Regression
Logistic regression is commonly used for classification tasks, but like linear regression, it can overfit when there are too many features or limited data. Regularization helps control overfitting by penalizing large parameter values.
1. Logistic Regression Cost Function (Without Regularization)
The standard cost function for logistic regression is:
where:
- is the sigmoid function,
- is the actual class label ( or ),
- is the number of training examples.
This cost function does not include regularization, meaning the model may assign large weights to some features, leading to overfitting.
2. Regularized Cost Function for Logistic Regression
To reduce overfitting, we add an L2 regularization term, similar to regularized linear regression:
where:
- is the regularization parameter (controls penalty),
- The term discourages large parameter values,
- (bias term) is NOT regularized.
✅ Effect of Regularization
- Small → Model may overfit (complex decision boundary).
- Large → Model may underfit (too simple, missing important features).
- Optimal → Model generalizes well.
3. Effect of Regularization in Gradient Descent
Regularization modifies the gradient descent update rule:
- The regularization term shrinks the weight values over time.
- Helps avoid models that memorize training data instead of learning patterns.
4. Decision Boundary and Regularization
Regularization also affects decision boundaries:
- Without regularization (): Complex boundaries that fit noise.
- With moderate : Simpler boundaries that generalize better.
- With very high : Too simplistic boundaries that underfit.
5. Summary
✅ Regularization in logistic regression prevents overfitting by controlling parameter sizes.
✅ L2 regularization (Ridge Regression) adds to cost function.
✅ Gradient Descent is adjusted to shrink large weights.
✅ Choosing is critical for a well-generalized model.